「word2vecで遊んでみた」 はてなニュース連動企画
実験背景など
2014-4-22
第一回の実験テーマとして「重たい解析処理」という事で色々考えていたのですが、なかなか良いものが浮かびませんでした。
そこで思いついたのが「株式会社はてなさん(http://www.hatena.ne.jp/)に相談しよう」です。
はてなさんというとエンジニアの集まる情報サイト運営のみならず、過去には自社サービス提供用のハードウェア環境をほぼ自前で構築していたという、IT猛者集団です。
早速相談してみたところ「word2vecというツールが結構重いよ」という情報を即答で頂きました。(流石です)
正直、「word2vecって何ですか?」という状態でしたが、教えて頂いたサイトで確認するとハードウェアスペックを必要としそうなプログラムである事は分かりました。
これなら、パソコン屋としてハードウェア面から色々試す事ができそうです。
そうしてお話を進める中でword2vecの具体的な使用例をはてなさん、ハードウェア性能による比較検証は弊社という役割分担で「word2vecで遊ぼう」(http://hatenanews.com/articles/201404/20050)という連動コンテンツを企画する運びとなりました!
弊社パートについては、プログラム知識が浅い上に検証時間に限りがありましたので、十分な情報とは言えないかもしれませんが、ハードウェア選定の一助になれば幸いです。
では早速word2vecの実験に入って参ります!
word2vecの準備
改めてWord2vecについてですが、Googleが無償で公開している自然言語処理の最新手法との事です。
そうしてその大きな特徴とは! ・・・十分に理解できておりませんので、詳しくは連動しているはてなさんのブログをご覧ください。
私達の役割は、ハードウェアの性能比較なので、計測環境の構築にポイントを置いて実験を進めます。
性能比較の実現の為には以下のポイントに留意してWord2vecのサイトで方法を模索して行きます。
・異なるハードウェア環境に対して同一の計測手法で速度を測る事が出来る
・お客様がご自身のパソコンでテスト環境を再現できる(出来るだけ無料で)
お客様が買い換えの必要があるかどうかを判断するには自分のパソコンと比較するのが一番です。
比較の結果、買い換え不要という事もよくあります。
テスト内容によっては難しい場合もありますが、今後も可能な限り上記2点を実現させたいと思います。
それではWord2vec公開サイトをチェックしてみましょう。
https://code.google.com/p/word2vec/
トップページにはサンプルとなるファイルの入手先やプログラムの実行例などの情報があります。
Word2vecのプログラムはこちらのリンクに置かれています。
Quick start
Download the code: svn checkout http://word2vec.googlecode.com/svn/trunk/
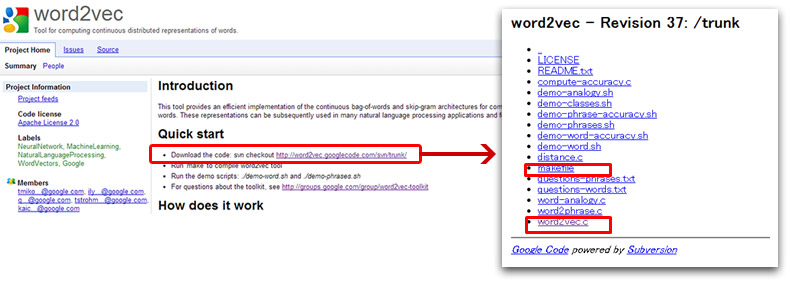
リンクの先にはライセンス規約やREADEME、シェルや
ソースファイルが置いてあります。
「Revision 37」は37という数字はここの情報更新の回数情報でしょうか?(数が変わったら内容確認してみます)
実行ファイルがあるのかと思っていたらLinuxでGCC使ってコンパイルしなさいという事のようです。
私はウィンドウズっ子なのですが頑張ります。
拡張子ですが、[.sh]はシェルスクリプト、[.c]はC言語のソースファイルです。
README以外の[.txt]の中にはサンプルデータとして使用するであろう単語群が書かれていました。
[makefile]がありますので、これで各実行ファイルを生成して行くのですね。
一番下に「word2vec.c」というソースがあります。
これが今回の実験で使用したプログラムです。
それ以外にも色々あるのですが、このプログラムと後述の「distance.c」というプログラム以外は時間の関係で試す事が出来ていません。 スミマセン。
Linuxをの操作・コマンド等を詳しく知らない私は、ソースを開いてテキストにコピペ→コンパイルという処理を行っていたところ、はてなさんから「“svn checkout”を使うと良いよ」と教えて頂きました。
ターミナル(端末)を立ち上げ以下のように打ちます。
svn checkout http://word2vec.googlecode.com/svn/trunk/
これで [ /home/%USERDIR% ] の直下に[ /trunk/] というフォルダと上記URLのソースの中身含めて生成されます。 便利ですね。
シェルスクリプトの中身を確認しましょう。
「demo-analogy.sh」というシェルスクリプトを開いてみました。
- make
if [ ! -e text8 ]; then
wget http://mattmahoney.net/dc/text8.zip -O text8.gz
gzip -d text8.gz -f
fi
echo -----------------------------------------------------------------------------------------------------
echo Note that for the word analogy to perform well, the models should be trained on much larger data sets echo Example input: paris france berlin
echo -----------------------------------------------------------------------------------------------------
time ./word2vec -train text8 -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1
./word-analogy vectors.bin
内容としては[TEXT8]というファイルを取得・解凍した後、この[TEXT8]を使ってword2vecを実行し、[vectors.bin]というデータを生成した後で、word-analogyで[vectors.bin]を実行しなさいという内容のようです。
他のシェルスクリプトも参照してみましたが、どれもTEXT8を元データとしてサンプルを生成しているものでした。
次にmakefaileの中身を確認します。
- make
CC = gcc
#The -Ofast might not work with older versions of gcc; in that case, use -O2
CFLAGS = -lm -pthread -Ofast -march=native -Wall -funroll-loops -Wno-unused-result
all: word2vec word2phrase distance word-analogy compute-accuracy
word2vec : word2vec.c
$(CC) word2vec.c -o word2vec $(CFLAGS)
word2phrase : word2phrase.c
$(CC) word2phrase.c -o word2phrase $(CFLAGS)
distance : distance.c
$(CC) distance.c -o distance $(CFLAGS)
word-analogy : word-analogy.c
$(CC) word-analogy.c -o word-analogy $(CFLAGS)
compute-accuracy : compute-accuracy.c
$(CC) compute-accuracy.c -o compute-accuracy $(CFLAGS)
chmod +x *.sh
clean:
rm -rf word2vec word2phrase distance word-analogy compute-accuracy
要約すると
[CC = gcc] CのコンパイラをGCCに指定。
[CFLAGS]には各種コマンドオプションを格納。
そうして順次コンパイルを実行して行くという内容となっています。
注釈文ですが、「古いGCCだと[-Ofast]は動かないかもしれないよ。もしそうなら[-O2]を使ってね」的な事を書かれています。
↓ここの赤文字を
CFLAGS = -lm -pthread -Ofast -march=native -Wall -funroll-loops -Wno-unused-result
↓こう書き換えるという意味
CFLAGS = -lm -pthread -O2 -march=native -Wall -funroll-loops -Wno-unused-result
調べてみますと、 [-Ofast]はGCCの4.7以降からの対応のようです。
試しに[-O2] と[-Ofast]の両方でコンパイルして速度を測ってみましたところ、大きな速度差があったので、もし古いGCCを使わなければならないという状況ではないのであれば、4.7以上のGCCへ更新される事をおすすめします。
その他のコマンドオプションについても各種最適化のオプションがあり、実際にオプション指定せずにコンパイルをかけたものと処理速度に大きな開きが出ました。
では実行ファイルを生成します。
ターミナル(端末)を立ち上げ、[ /home/%USERDIR% /trunk/]にディレクトリ移動して[make]と入力するとコマンドオプションが反映された実行ファイルが生成されます。
生成された[wordd2vec]と[distance]は後の実行の為[ /home/%USERDIR% /]下に移動しておきます。
[Word2vec.c]と[distance.c]だけをコンパイルかけるなら[ /home/%USERDIR% /]下に[Word2vec.c]を置いて直接下記のように打って頂いても大丈夫です。
GCC ver4.7以上の場合
gcc word2vec.c -o word2vec -lm -pthread -Ofast -march=native -Wall -funroll-loops -Wno-unused-result
gcc distance.c -o distance -lm -pthread -Ofast -march=native -Wall -funroll-loops -Wno-unused-result
GCC ver4.7以下の場合
gcc word2vec.c -o word2vec -lm -pthread O2 -march=native -Wall -funroll-loops -Wno-unused-result
gcc distance.c -o distance -lm -pthread -O2 -march=native -Wall -funroll-loops -Wno-unused-result
ちなみにファイルやディレクトリをいちいち移動しているのは私がLinuxでのパスの切り方を本日時点で分かっていないからです。 修行します。
ベンチマーク手法の模索
ではベンチマーク方式について考えます。
※実行ファイルについては、先のページまでの条件で生成されている事を前提としています。
まずは、word2vecのベンチマークです。
速度を図っている人達の方式を確認すると、ファイルはTEXT8を使用して各種パラメータの数字も触らずこのまま実行して速度を記載されているパターンが多いようでした。
time ./word2vec -train text8 -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1
例えば[-cbow]は「continuous bag-of-words」に関する何かであり、数値を変えると処理速度が変わる事も確認しましたが、そもそも「bag-of-words」とは何かという概念理解からスタートが必要なのでそのままにします。
-threadsは言葉そのまんまのスレッド本数のようなので、ここは触ってみました。
ソースを改良して速度アップさせている人も見受けましたが、今回はハード的な検証目的の為、ソースコードも基本的にそのまま使用します。(Revision変更で速度は今後、変わるかもしれませんが)
[TEXT8]のファイルは繰り返し使用するので、シェルスクリプトではなく事前にダウンロードして解凍したものを用意して直接上記のコマンドを実行するという方法を取る事にしました。
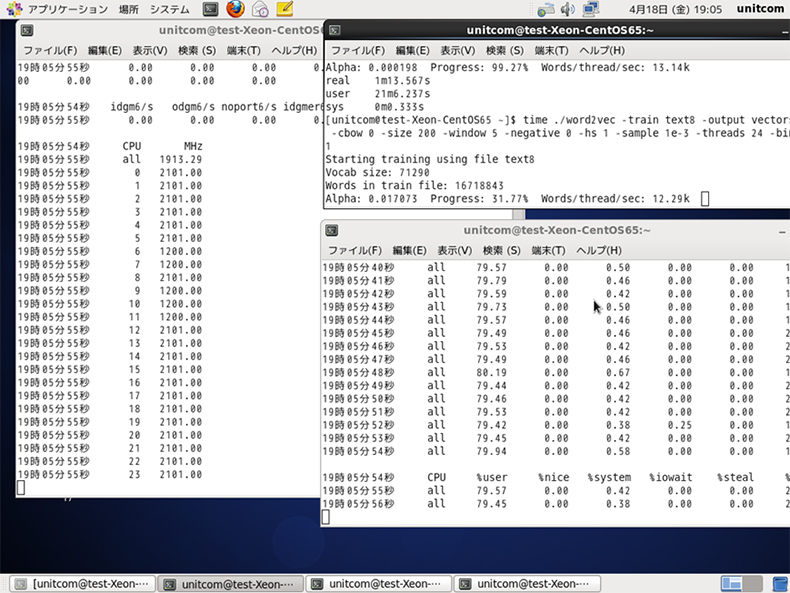
実際にプログラムを実行した画面です。
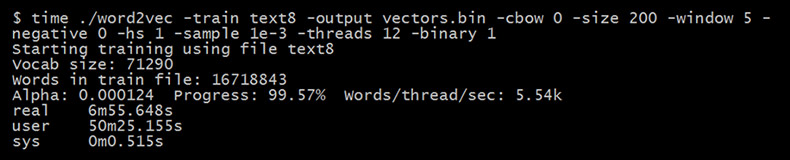
※こちらの画像は比較実験前にWin7上でCygwinのGCCでコンパイルかけたword2vecを実行したものです。
Words/thread/sec: で1スレッドごとの処理数が出ています。
ここは名前の通りThreadごとの処理効率を表しているので、Hyper ThreadingのEnable、Disableも反映されるのと、適当な日本語分ち書きファイルを準備して処理したら[TEXT8]と異なる数値となり、内容によって数値が変わるようでした。
今回のようにTEXT8という同一のファイルでは指標になりますが、処理するテキストファイルが異なる場合は参考値となります。
[time]コマンドはLinuxのコマンドで、指定したプログラムの実行時間を図るものです。
それぞれ下記のような内容になります。
real:プログラムの呼び出しから終了までにかかった時間(実時間)
user:ユーザーモードとなっていた時間
sys :カーネルモードとなっていた時間
userは1スレッドベースの結果でHyper Threading Enableの場合はとても遅く見えてしまいます。
realは実際にかかった時間です。
以上の事から、word2vecのプログラムについては、基本はrealの処理時間で、同一ファイルの場合はwords/thread/sec の時間も比較しながら判断して行く事としました。
次にword2vecで作成したファイルを実際に動かしてみるという場合を想定しての検証について考えます。
実際の使用においては、皆さん数GB分の単語を準備しているようです。
(ちなみに、はてなさんの準備したファイルは元ファイル約10G、word2vecでの処理後ファイルで約1.2Gになったとの事です)
[TEXT8]はあくまでちょっとしたデモ用ファイルなので、容量が少なくこの評価には使えません。
Wikipediaや辞書等に処理を掛けて遊ぶパターンがあるようですが、これだと人によって収集データやその後の処理方法に違いが出てしまいます。
困ったな~ とあれこれ考えていたのですが、良いサンプルがword2vecのサイトにありました。
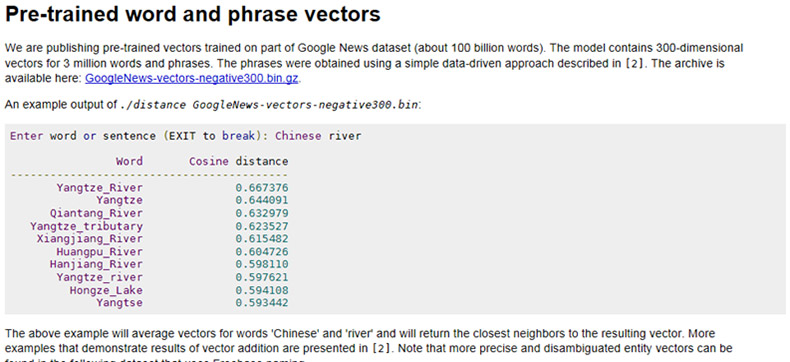
TOPページ中央部にある、こちらの「GoogleNews-vectors-negative300.bin.gz」というファイルです。
展開するとなんと、3.39GBもの容量になります。
これを紹介されているようにdistanceで処理した結果で測る事ができそうです。
./distance GoogleNews-vectors-negative300.bin
この場合は、上記のようにワード入力してから結果が帰って来る時間の計測が必要なので、timeコマンドは使えません。
なのでアナログですがストップウォッチでdistanceの実行完了と、「Chinese river」という単語を打って応答が帰るまでの時間を図ってみる事にしました。
ベンチマーク手法の模索
ソフトウェアの動きをつかんだところでどのようなハードウェアで試すかを考えてゆきます。
実験工房の基本的な考え方は「使いたいソフトウェアに対してコストパフォーマンスの良いハードウェアはどれかを調べる」です。
今回もデータ分析がもっと身近になるようにという思いを込めて、一般的なパソコンの構成でコストパフォーマンスの良い構成を調べるという事を重視して、はてなさんにも一般的なハードウェアスペックでのパソコンをお送りさせて頂きました。
がっ・・しかし・・・その3日後に・・・ どうしても気になって結局、XEONでワークステーション構成のマシンを準備して調べてしまいました。
もしかするとこれが爆速かもしれません。
ちゃんと比較してはてなさんにお渡しすれば良かったですよね。 ごめんなさ~い。
という訳で以下の2つのベースでチェックしました。
パソコン構成
CPU:
Intel Corei7-4770 i5-4670 i3-4340
マザー:
ASUS H87M-E (intel H87 チップセット M-ATX)
メモリ:
DDR3-1600 8GB *2 枚, 計 16 GB
DDR3-1600 8GB *1 枚, 計 8 GB
DDR3-1600 4GB *2 枚, 計 8 GB
DDR3-1600 4GB *1 枚, 計 4 GB
ワークステーション構成
CPU:
Intel Xeon E5-2620v2 x2
マザー:
ASUS Z9PA-D8C
メモリ:
DDR3-1866 16GB *8 枚,計128GB
足回りは同一スペックです。
SSD:
CFD販売 CSSD-S6T128NHG5Q [128MB SRead:530MB/s SWrite:490MB/s]
HDD:
Tosshiba DT01ACA050 [500GB SATA600 7200rpm]
OS:
CentOS 6.5 ※はてなさん環境に合わせる為
検証のポイントは以下の通りです。
CPU性能
・物理コア数による差
・仮想コア数による差
・周波数による差
メモリー
・各処理での必要容量
・メモリー帯域の影響(Dual,Singleでチェック)
・メモリーからあふれた際の挙動(エラー or Disk書込み発生)
ストレージ
・通常時のHDDとSSDの速度差
・メモリーからあふれた際のHDDとSSDの速度差
CPUコア単発のクロック、物理・論理のコア数、キャッシュなど、どの要素の影響を受けるのかで結果は異なります。
Hyper-Threadinが効きにくい処理の場合にはCore i7 よりi5のほうがコスパが圧倒的に良くなる事があります。
メモリーも不要な容量を積まない、SSDも効果が出ないなら使用しないという判断ができるように計測して行きます。
CentOS 6.5での環境準備
Linuxを常時使用している人には釈迦に説法ですが、ウィンドウズっ子の私としては色々苦労しましたので、ポイントをご紹介しておきます。
①OSインストール
CentOS のパッケージモジュールのインストールオプションでは、手動を選択 (『今すぐカスタマイズ』を選んで)します。
開発ツールのところで、gcc 関係はすべて選択してください、(リソースモニタの sysstat もここで入ります)
②「Developer Tools 」のインストール GCCでコンパイルを掛けようとしたら、エラーになってしまいました。
何かが足りないようです・・・
トラブルシューティングの時間もなかったので、開発ツール関係を一括でインストールしてしまいました。
管理者ユーザーに変更して「Developer Tools」をインストールしてください。
-
$ su
パスワード: *****
# yum groupinstall ”Developer Tools”
③GCC4.8.2のインストール
CentOS に標準でインストールされるGCCのバージョンは4.4.7でした。
ネット上であれこれと調べたところ、より新しいバージョンのGCCがありました。
その中でも、4.8.2 が新しくなおかつよさ気なので早速インストールします。
まず、ネット上から、gcc-4.8.2.tar.gz というファイルを探してダウンロードしましょう。
これも管理者ユーザーで下記要領でインストールしました。
-
$ su
パスワード: *****
# tar zxvf gcc-4.8.2.tar.gz -C /usr/local/src
# cd /usr/local/src/gcc-4.8.2
# ./contrib/download_prerequisites
# yum install glibc-devel.i686
# ./configure
# make
# make install
# make のところで、2 時間以上かかってしまいました。
尚、Windows環境下で今回の実験を行いたいというお客様は、Cygwin(http://www.cygwin.com/)を使用してみてください。
実験前の下調べにWindws7 64bit下でインストールして、word2vecの動作を確認いたしました。
オプションインストールに抜けがあると、コンパイルでエラーになるので、時間はかかりますが、フルオプション選択でのインストールがお勧めです。
word2vecの検証
それではまず、word2vecの実行について検証して行きます。
time ./word2vec -train text8 -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3
-threads 12 -binary 1
基本的にこちらのパラメータでファイルは[TEXT8]で[-threads]の数を変えながら比較を進めます。
コンパイル時のコマンドオプション指定の違い、同CPUでの別条件による性能差の検証を行った後にCPU別の比較を行って結論を出したいと思います。
検証1:GCCのバージョンによる差
事前の調査でコマンドオプションの違いにより速度が異なる事が分かりましたので、GCCのバージョンを変更してver4.8.2=[-ofast]、ver4.4.7=[-o2]とコマンドオプションを指定してコンパイルした結果の比較を行いました。
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i7-4770 | 16GB | Dual | HDD | Enable | 12 | 4.8.2 | 0m27.731 | 3m22.652 | 0m0.171 | 83.05 |
| 4.4.7 | 1m8.367 | 8m39.077 | 0m0.182 | 32.22 |
※表の項目名補足
メモリー:Memory=総容量、Channel=Single or Dual
Storage:HDD or SSD
HT:Hyper ThreadingのEnable or Disable
-threads=word2vecでの指定数
w/t/s=word2vecの計測結果Words/thread/secの略
結果はご覧の通り(黄色の部分)で4.8.2が倍以上早い結果となりました。
マルチスレッドプログラムにおけるコンパイラやコマンドオプションの重要性を目の当たりにしました。
実は本実験の最中にGCC ver4.9が公開されましたが今回はテスト結果への反映が間に合いませんでした。
これはまた次回の機会で試して行きたいと思います。
CentOS6.5では4.4.7でお使いのユーザー様も多いかもしれませんので、4.4.7と4.8.2の両方の結果を掲載してゆきます。
検証2:Hyper ThreadingとThread数指定の関係
プロブラムによっては、同じThread数指定でHyper ThreadingのEnable、Disableが結果に影響する場合がありますので先に調べておきます。
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i7-4770 | 16GB | Dual | HDD | Disable | 1 | 4.8.2 | 1m36.740 | 1m36.623 | 0m0.120 | 177.14 |
| 1 | 4.4.7 | 5m11.394 | 5m11.303 | 0m0.128 | 54.11 | |||||
| Enable | 1 | 4.8.2 | 1m38.339 | 1m37.428 | 0m0.128 | 175.69 | ||||
| 1 | 4.4.7 | 5m11.685 | 5m11.593 | 0m0.113 | 54.06 | |||||
| Disable | 4 | 4.8.2 | 0m33.690 | 2m5.987 | 0m0.171 | 134.88 | ||||
| 4 | 4.4.7 | 1m28.996 | 5m43.479 | 0m0.263 | 48.94 | |||||
| Enable | 4 | 4.8.2 | 0m33.970 | 2m7.416 | 0m0.118 | 133.38 | ||||
| 4 | 4.4.7 | 1m28.600 | 5m44.939 | 0m0.124 | 48.73 |
Corei7-4770は物理コア数4、HTにより論理コア数4で系8コアのCPUです。
これを同じスレッド数指定で変化があるかを調べます。
物理コア数として有効な1~4で[-thread]の数値を変更して比較した結果としては、誤差の範囲となりました。
今後のテストでは、Hypert Threadingについて機能ありのものを特にDisableにせずに進めてゆきます。
CPUリソースの消費をリソースチェックのsarコマンドで確認したところ、Thread=1で25%、4で100%近い位置を指していて、指定の範囲でフルに使用されていました。
検証3:仮想コアの性能への影響
Corei7-4770は物理コア数の4でThread指定して計測した段階でCPUリソースは100%近く消費していました。 このようにデータ処理量が多い状況でHyper Threadingが有効なのかをチェックします。
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i7-4770 | 16GB | Dual | HDD | Enable | 4 | 4.8.2 | 0m33.970 | 2m7.416 | 0m0.118 | 133.38 |
| 5 | 4.8.2 | 0m32.674 | 2m26.798 | 0m0.141 | 115.51 | |||||
| 8 | 4.8.2 | 0m27.838 | 3m22.172 | 0m0.177 | 83.43 | |||||
| 9 | 4.8.2 | 0m28.173 | 3m19.737 | 0m0.167 | 84.50 | |||||
| 12 | 4.8.2 | 0m27.731 | 3m22.652 | 0m0.171 | 83.05 | |||||
| 4 | 4.4.7 | 0m28.6000 | 5m44.939 | 0m0.124 | 48.73 | |||||
| 5 | 4.4.7 | 0m28.962 | 6m30.510 | 0m0.123 | 43.02 | |||||
| 8 | 4.4.7 | 0m8.179 | 8m40.677 | 0m0.178 | 32.18 | |||||
| 9 | 4.4.7 | 0m8.862 | 8m37.683 | 0m0.203 | 32.38 | |||||
| 12 | 4.4.7 | 0m8.367 | 8m39.077 | 0m0.182 | 32.22 |
Corei7-4770は論理コア4の合計8コアとなりますので、Threads 4までが物理コア数の領域を軸として、論理に入る5、物理+論理の8、そこを越える9と12でどのようになるかを計測しました。
4.4.7では30秒ほどの速度差がついて、Hyper Threadingがあったほうが明らかに良いですが、4.8.2ではその差はかなり少なくなっています。
検証4:メモリー帯域による性能差
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i7-4770 | 16GB | Dual | HDD | Enable | 12 | 4.8.2 | 0m27.731 | 3m22.652 | 0m0.171 | 83.05 |
| 8GB | Single | 12 | 4.8.2 | 0m27.098 | 3m11.913 | 0m0.188 | 87.78 | |||
| 16GB | Dual | 12 | 4.4.7 | 1m8.367 | 8m39.077 | 0m0.182 | 32.22 | |||
| 8GB | Single | 12 | 4.4.7 | 1m8.294 | 8m39.402 | 0m0.201 | 32.19 |
大容量ファイルを扱うのでメモリー帯域の影響を見る為、シングルチャネル、デュアルチャネルで比較しましたが差はありませんでした。
検証5:大容量ファイル時のディスクスワップ対策が必要か
お手軽にベンチマーク比較できるようにTEXT8での比較を進めましたが、大容量処理も検証しておきたかったのでこれは別途テスト用に17GBのファイルを生成しました。(生成方法は後ページで紹介しております) 時間の関係で4.8.2のみのチェックとなりますが、ご了承ください。
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i7-4770 | 16GB | Dual | HDD | Enable | 12 | 4.8.2 | 86m59.597 | 641m1.459 | 0m30.320 | 85.78 |
| 8GB | 4.8.2 | 86m33.589 | 641m11.391 | 0m30.641 | 85.79 | |||||
| 16GB | SSD | 4.8.2 | 87m13.295 | 641m45.642 | 0m30.880 | 85.71 |
16GBのメモリーでも100%近い数値で推移しますが念のため8GBまで落としても計測しました。
ディスクスワップで速度落ちるかなと思いましたがSSDに変更しても速度は変わりませんでしたので、メモリーは適量あれば良さそうです。
検証6:CPUによる処理速度の差
| CPU | 通常時 | TB時 | 物理Core | HT | Cash |
|---|---|---|---|---|---|
| Core i7-4770 | 3.4 | 3.9 | 4 | 4 | 8mb |
| Core i5-4670 | 3.4 | 3.8 | 4 | 0 | 6mb |
| Core i3-4340 | 3.6 | - | 4 | 2 | 4mb |
| Xeon E5-2620v2 | 2.1 | 2.6 | 6 | 6 | 15mb |
Corei7が圧倒的な性能のような印象をお持ちの方も多いかもしれませんが、実は上記の通り、なかなかに絶妙な性能差になっていて、処理の内容によっては実はi7でなくても良いという事はよくある話です。
安価なマシンで処理できるに越した事はありませんので、それぞれ比較してみました。
又、特別ゲストとしてXeon E5-2620V2の参戦です。
単発のコアクロックは低いですが、物理コア6 論理コア6の12コアで更に2ソケットの系24スレッドの処理が可能となっています。
ではまずは、Core iシリーズから見てみます。
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i3-4340 | 16GB | Dual | HDD | Enable | 1 | 4.4.7 | 5m37.582 | 5m37.223 | 0m0.126 | 49.97 |
| Core i5-4670 | 16GB | Dual | HDD | - | 1 | 4.4.7 | 5m38.240 | 5m37.119 | 0m0.179 | 49.98 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 1 | 4.4.7 | 5m11.685 | 5m11.593 | 0m0.113 | 54.06 |
| Core i3-4340 | 16GB | Dual | HDD | Enable | 2 | 4.4.7 | 2m55.389 | 5m46.451 | 0m0.171 | 48.60 |
| Core i5-4670 | 16GB | Dual | HDD | - | 2 | 4.4.7 | 2m55.702 | 5m47.114 | 0m0.129 | 48.51 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 2 | 4.4.7 | 2m41.869 | 5m20.355 | 0m0.119 | 52.55 |
| Core i5-4670 | 16GB | Dual | HDD | - | 4 | 4.4.7 | 2m13.952 | 8m34.237 | 0m0.214 | 32.63 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 4 | 4.4.7 | 1m28.600 | 5m44.939 | 0m0.124 | 48.73 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 12 | 4.4.7 | 1m8.367 | 8m39.077 | 0m0.182 | 32.22 |
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i3-4340 | 16GB | Dual | HDD | Enable | 1 | 4.8.2 | 1m36.619 | 1m35.796 | 0m0.160 | 179.37 |
| Core i5-4670 | 16GB | Dual | HDD | - | 1 | 4.8.2 | 1m22.069 | 1m21.741 | 0m0.112 | 210.04 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 1 | 4.8.2 | 1m38.339 | 1m37.428 | 0m0.128 | 175.69 |
| Core i3-4340 | 16GB | Dual | HDD | Enable | 2 | 4.8.2 | 0m57.224 | 1m51.126 | 0m0.136 | 153.93 |
| Core i5-4670 | 16GB | Dual | HDD | - | 2 | 4.8.2 | 0m49.014 | 1m35.352 | 0m0.107 | 179.32 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 2 | 4.8.2 | 0m57.928 | 1m52.656 | 0m0.114 | 151.39 |
| Core i5-4670 | 16GB | Dual | HDD | - | 4 | 4.8.2 | 0m30.140 | 1m51.584 | 0m0.197 | 152.44 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 4 | 4.8.2 | 0m33.970 | 2m7.416 | 0m0.118 | 133.38 |
| Core i7-4770 | 16GB | Dual | HDD | Enable | 12 | 4.8.2 | 0m27.731 | 3m22.652 | 0m0.171 | 83.05 |
処理速度の優劣なので、それぞれ最大実行可能スレッドでの速度を見れば良いですが同一スレッド下での比較も一応、掲載しておきます。
4.4.7ではCore i7が圧勝ですが、4.8.2ですと、Core i5がかなり競った数字となりました。
さあいよいよお楽しみのXEONの計測です!
どんな速度になるのでしょうか~~!?
| CPU | Memory | Channel | Storage | HT | -threads | GCC Ver | time/real | time/user | time/sys | w/t/s |
|---|---|---|---|---|---|---|---|---|---|---|
| 2620V2 | 128GB | Dual | HDD | Enable | 4 | 4.8.2 | 1m16.136 | 4m40.499 | 0m0.303 | 60.30 |
| 8 | 4.8.2 | 1m10.780 | 8m33.767 | 0m0.343 | 32.70 | |||||
| 12 | 4.8.2 | 1m14.239 | 13m49.754 | 0m0.383 | 20.15 | |||||
| 24 | 4.8.2 | 1m13.446 | 20m17.296 | 0m0.349 | 13.68 | |||||
| 4 | 4.4.7 | 2m45.228 | 10m46.137 | 0m0.302 | 25.99 | |||||
| 8 | 4.4.7 | 1m38.522 | 12m11.988 | 0m0.257 | 22.91 | |||||
| 12 | 4.4.7 | 1m28.863 | 15m51.888 | 0m0.340 | 17.56 | |||||
| 24 | 4.4.7 | 1m20.998 | 12m23.587 | 0m0.369 | 12.97 |
・・・あれ? ・・・遅い?
Sarコマンドで確認したところCPUを79%しか使う事が出来ておらず、コアの使用変遷を眺めていても18~20コア以上を使っている様子はありません。
指定できるスレッド数の上限はその辺らしいです。
単発のクロック数が遅いのも重なり、期待する性能といえるものにはなりませんでした。。
残念でしたが、こういう事が分かるのも楽しみの一つです。
はてなさんには結果オーライで丁度良いマシンを渡せましたし、今後プログラムの更新で異なる結果となるかもしれませんので期待して待つ事にしましょう。
distanceの検証
先に紹介しております「GoogleNews-vectors-negative300」を使用した比較を行います。
「distance.c」をコンパイルして/home/%USERDIR% 下に「distance」、 「GoogleNews-vectors-negative300.bin」を置いてください。
・ベンチマーク方法
こちらのコマンドを打って帰ってくるまでの時間 ※下部エクセルの項目名:作成1回、2回
./distance GoogleNews-vectors-negative300.bin
※起動後1回目の処理と2回目以降キャッシュが効いた状態での処理時間
「Chinese river」という単語を入力して帰ってくるまでの時間 ※下部エクセルの項目名:単語入力
それぞれストップウォッチで計測しました。 ※したがってコンマ以下の誤差は結構あります。
「Chinese river」は単純にサンプルの例に書かれていたワードだからです。
単語の違いによる時間の差は特に感じませんでした。 (格納されていない単語はエラーで弾かれます)
結果はこちらです
| CPU | HT | Memory | Channel | Storage | 作成1回目 | 作成2回目 | Chinese river |
|---|---|---|---|---|---|---|---|
| Core i7-4770 | Enable | 4 | Single | HDD | 34.38 | 32.61 | 59.38 |
| 4 | Single | SSD | 15.55 | 17.15 | 20.25 | ||
| 8 | Dual | SSD | 11.06 | 11.01 | 1秒以下 | ||
| 8 | Single | SSD | 11.4 | 10.96 | 1秒以下 | ||
| 16 | Dual | SSD | 11.25 | 10.81 | 1秒以下 | ||
| 16 | Dual | HDD | 21.21 | 12.03 | 1秒以下 | ||
| Core i5-4670 | - | 16 | Dual | HDD | 20.43 | 10.23 | 1秒以下 |
| Core i3-4340 | Enable | 16 | Dual | HDD | 20.48 | 11.76 | 1秒以下 |
この処理ではメモリーの消費を見ていると元ファイルの倍程度の容量を消費しているのが見て取れました。
3.39GBのファイルですが、8GB時で97%位まで消費します(システム領域分含み)
「ようやくデスクスワップ状況作れるじゃん」という事で4GBで見てみた結果、上記のようになりました。
SSDにすると作成処理は早くなりますが、ここは上記のように数秒の範囲なので、一日に何回も処理をする人でない限りストレスは感じないのではないでしょうか。
CPUやコンパイル時のオプション指定の違いによる速度差はほぼ分かりませんが、メモリーが少ないと極端に遅くなります。
特に単語入力後の戻りが非常に遅く、メモリーが十分にあると一瞬で終わる処理に上記のような時間がかかる結果となりました。
作成処理は初めの一回のみなので我慢できますが、単語入力は繰り返し入力すると思いますので、このような状況になるとストレス溜まると思われます。
ただ、はてなさんの今回のデータが元10GBで生成後に1.2GBです。
昨今のメモリーの価格なども考えますと、なかなかこのような状況にならないのではないかと思います。
大容量の検証用ファイルを作る
今回のチェックでは大半をTEXT8を使用して行い、基本的な比較はそれで良いと思いますが、メモリー消費とその影響などを調べる上で大容量ファイルも生成しましたので、その方法をご紹介いたします。
word2vecのページに「Where to obtain the training data」というトレーニングデータに関する項目があります。

Matt Mahoney‘s page (http://mattmahoney.net/dc/textdata.html)を開くと内容を確認する事ができます。

[enwiki9]というファイルが1GB近くあるようです。
中を見るとWikipedia英語版のxmlファイルを元にしたデータでした。
このファイルは[TEXT8]と異なり、わかち書きなどの前処理を終えていないものなので、処理が必要です。
このページを最下部までスクロールすると、Perl を使用した処理について紹介されていました。

「Appendix A」と書かれた場所より下を確認すると概要とソースコードが紹介されています。
perlをインストール後、 ソースコードを[wikifil.pl]で作成して(名前は任意)、下記のコマンドで変換処理を実行してください。
perl wikifil.pl enwik9 > text
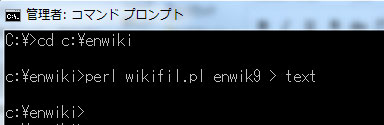
WindowsでPeal環境を準備して実行してみたところです。
[enwiki]というフォルダにファイルを置いて実行すると、このフォルダ内に[TEXT]というファイルが出来ます。

TEXTを参照してみるとこのようなテキストに生まれ変わっていました。
ちなみにこちらの英語版wikiの過去ログコーナーからダウンロードしたもっと大きなファイルの変換処理もできました。 今回用意した17GBのテストファイルはこちらから生成したものです。
http://dumps.wikimedia.org/enwiki/
興味のあるお客様は是非、お試しください。
※perl環境の準備についての解説はページボリュームの都合などで割愛させて頂きます。
(ご要望が多ければ後日ご紹介させて頂きます)
まとめ
Word2vec
・コンパイル時のコマンドオプションにより速度差がかなり異なる
・Hypert Threadingも多少は効くが最新コンパイラでは恩恵が少なくなった
・メモリーは処理するファイル分あれば良い
・SSDによる性能の恩恵は少ない
distance
・CPU性能による差は少ない
・メモリーの容量は実行ファイルの倍よりちょっと多い程度必要
・メモリーの容量を超えるとディスクスワップで速度激減
word2vecの処理マシンは現状では、ワークステーションベースではなくパソコンベースのスペックで良く、できる事ならGCCは新しいバージョンで使用する事がお勧めという事になります。
それとビジネスマシンとしてCore i5のバランスはやっぱり良いなというのを再確認した次第です。
ちょっと試したい位の人にはCore i5をおすすめします。
Core i3についても生成されたベクトルファイルを操作する分には速度差はありませんでしたので、生成処理の時間を我慢できるのであれば十分に使えます。
今回は試せなかったですが、X79チップセットベースでCore i7-4930(3.4-3.9GHz/6コア/12スレッド)が最強なのかどうかは確認する必要があると思っていますので追って実験してみます。
執筆:パソコン実験工房 職人1号
