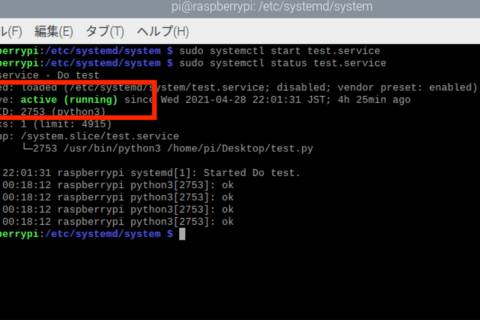
Raspberry piは、音声認識エンジンを組み合わせて、マイクから入力された音声が言葉かどうか、またそれがどんな言葉なのかを認識させることができます。 今回は、オープンソースの音声認識エンジン「Julius(ジュリアス)」を用いて、JuliusのインストールからJulius付属のディクテーション(dictation≒自動書き取り)キットを用いた音声認識と、特定の言葉を認識させるための辞書データ作成、辞書データを用いた特定の単語認識まで、詳しい手順をご紹介します。
Raspberry Piで音声認識を行う仕組み
Juliusとは音声認識システムを開発・研究するためのオープンソースソフトウェアです。
音の波形データと、単語の読みが定義された辞書データ、単語同士のつながりなどのデータを用いながら、マイク等から入力された音声の文字列とあらかじめ登録しておいた辞書の単語のデータを比較して、最も近い単語を割り出します(下図)
 Raspberry PiとJuliusによる音声認識の流れ
Raspberry PiとJuliusによる音声認識の流れ
音声認識エンジンJuliusのセットアップ
では、実際に使うためにRaspberry piにJuliusの環境をインストールしていきましょう。
はじめに、Github のJuliusのサイトからソースコードを取得します。
まず、空のディレクトリを作成してください。
mkdir julius
 空のディレクトリを作成
空のディレクトリを作成
作成した「julius」ディレクトリに移動します。
cd julius
 「julius」ディレクトリに移動
「julius」ディレクトリに移動
「julius」ディレクトリファイル内で、Github のJuliusのサイトからソースコードをダウンロードします。
wget https://github.com/julius-speech/julius/archive/v4.4.2.1.tar.gz
 Github からソースコードをダウンロード
Github からソースコードをダウンロード
ダウンロードしたら、ファイルを解凍します。
tar xvzf v4.4.2.1.tar.gz
 ダウンロードしたらファイルを解凍する
ダウンロードしたらファイルを解凍する
解凍したファイルの中から、「julius-4.4.2.1」ファイルに移動します。
cd julius-4.4.2.1
 ライブラリーをインストールする
ライブラリーをインストールする
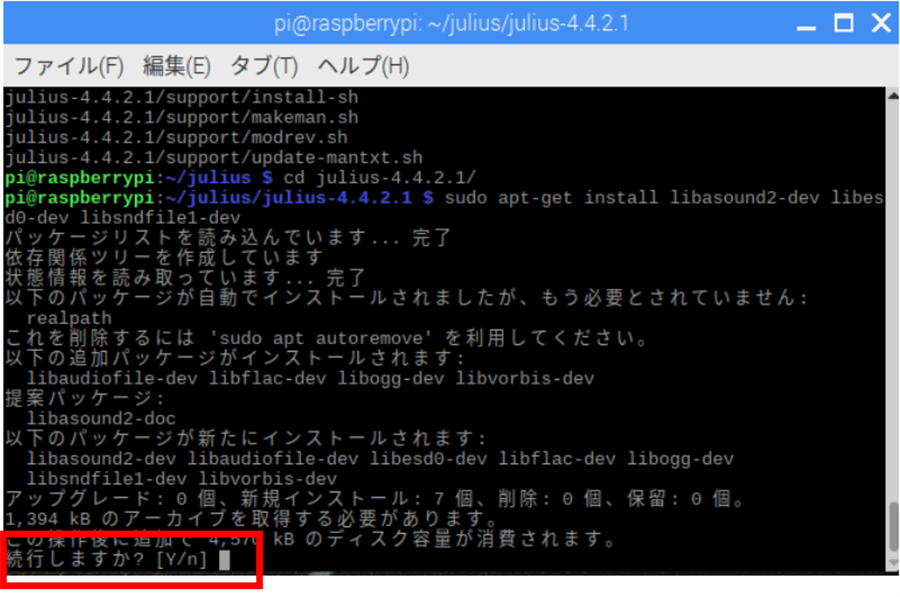
今回の作業に必要なライブラリーを入れます。
sudo apt-get install libasound2-dev libesd0-dev libsndfile1-dev
 「Y」キーを押して実行する
「Y」キーを押して実行する
図の画面で止まった場合は「Y」キーを押して実行します。
ライブラリーを入れたらコンパイルをします。
./configure --with-mictype=alsa
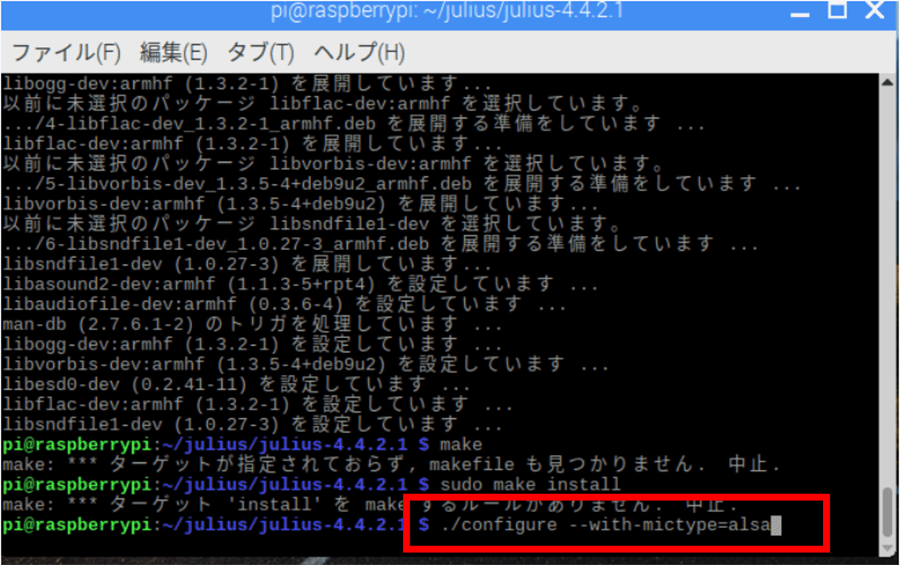
続いてこのコマンドを実行します。
make
sudo make install
 コンパイルする
コンパイルする
これで、Raspberry piでJuliusを使用する環境が整いました。
次に、ディクテーションキットをセットアップしていきましょう!
ディクテーションキットのセットアップ
ここからは、Juliusを実行するために必要な音声認識パッケージ「ディクテーションキット」をダウンロードします。ディクテーションキットは「ディクテーション(聞いた言葉の書き取り)」という言葉のとおり、音声を認識して文字として書き出すために必要な日本語の音響・言語データが収められています。
先ほどJuliusをインストールした流れと同様に、まずディクテーションキットのためのファイルを作成します。作成は、「/julius/」内で行うようにしてください。
この場所で下記のコマンドを実行して
cd ../
 「julius」ディレクトリに移動
「julius」ディレクトリに移動
ファイル移動ができたら、ファイルを作成します。
mkdir julius-kit
 空のディレクトリーの作成
空のディレクトリーの作成
続いてこのコマンドを実行します。
cd julius-kit
 「julius-kit」ディレクトリーに移動する
「julius-kit」ディレクトリーに移動する
ディクテーションキットをダウンロードします。
wget https://osdn.net/dl/julius/dictation-kit-v4.4.zip
 ディクテーションキットをダウンロード
ディクテーションキットをダウンロード
ダウンロードしたファイルを解凍します。
unzip dictation-kit-v4.4.zip
 ファイルの解凍
ファイルの解凍
これで完了です。
続いて、USBマイクをセットアップします。
USBマイクのセットアップ
今回はUSBマイクを使用します。Juliusの仕様上、USBマイクの優先順位を上げる必要があるため、最初に設定を行います。
まずraspberry piにマイクをUSB接続し、ターミナル上で下記のコマンドを実行します。
cat /proc/asound/modules
コマンド実行の結果、「snd_usb_audio」が0番でなかった場合、下記の設定を行います。
 「snd_usb_audio」が0番ではなかった場合
「snd_usb_audio」が0番ではなかった場合
マイクでの入力を行うために、サウンドデバイスの優先順位を変更します。今回使用するマイクがUSB接続のマイクになるので、USBデバイスの優先順位を内蔵しているサウンドデバイスよりも上にします。
ターミナル上で下記のコマンドを実行します。
sudo vim /etc/modprobe.d/alsa-base.conf
 サウンドデバイスの設定ファイルを開く
サウンドデバイスの設定ファイルを開く
Vimエディタが立ち上がるので、下記のコードを入力して保存し、Vimエディタを閉じてください。
options snd slots=snd_usb_audio,snd_bcm2835 options snd_usb_audio index=0 options snd_bcm2835 index=1
 サウンドデバイスの設定
サウンドデバイスの設定
ターミナル上で下記のコマンドを実行をします。
sudo vim ~/.profile
 Raspberry Piの設定ファイルを開く
Raspberry Piの設定ファイルを開く
Vimエディタが開くので、下記のコードを一番最後の行に追記し、保存してVimエディタを閉じてください。
export ALSADEV="plughw:0,0"
 Raspberry Piの設定ファイルを編集する
Raspberry Piの設定ファイルを編集する
今のコードで、Raspberry piが立ち上がるたびにサウンドデバイスの設定を読み込まれるように、設定ファイルを編集しました。
その他ライブラリーのセットアップ
この他にも必要なライブラリーをインストールするため、ターミナル上で以下のコマンドをそれぞれ実行します。
sudo apt-get install alsa-utils sox libsox-fmt-all
上記コマンドにより、下記がインストールされます。
- alsa-utils —サウンド機器を利用するために必要なプログラムをまとめたもの
- sox —SoXコマンドラインで音声ファイルを操作するためのツール
- libsox-fmt-all —SoXでmp3などのオーディオ形式を扱うためのプログラム
 ライブラリーのインストール
ライブラリーのインストール
sudo sh -c "echo snd-pcm >> /etc/modules"
コマンドを実行したら、Raspberry piを再起動します。
これでUSBマイクの設定の環境を構築することができました。
 再起動後設置の確認
再起動後設置の確認
音声認識が可能かどうか確認する
JuliusとUSBマイクの環境を整えることができたので、実際にJuliusのディクテーションキットを使用して、マイクから入力した音声を認識できる状態か確認します。
ターミナル上で、下記のコマンドを入力してください。
cd ~/julius/julius-kit/dicration-kit-v4.4/
 「dicration-kit-v4.4」ディレクトリー内に移動
「dicration-kit-v4.4」ディレクトリー内に移動
続けて、このコマンドを実行します。
julius -C main.jconf -C am-gmm.jconf -demo
 デモを実行してみる
デモを実行してみる
コマンドを実行すると下図のような画面になり、何か話しかけると音声を認識できる状態であることが確認できます。
 「please speak」と出ており、音声を認識できる状態であることが確認できる。
「please speak」と出ており、音声を認識できる状態であることが確認できる。
 話しかけると認識された言葉が表示される。
話しかけると認識された言葉が表示される。
実際に話しかけてみましたが、話した言葉とは異なる言葉として認識されることが多く、精度は充分でないようです。
独自辞書データで音声認識の精度を上げる
先ほど、実際にJuliusのディクテーションキットを使用して音声認識を試してみましたが、上記の通りあまり高い精度は得られませんでした。
音声認識には、辞書データと呼ばれるデータが必要です。そのデータが強力なら強力であるほど、精度よく音声認識することができます。精度の良い辞書データを作成することはなかなか難しいのですが、独自の辞書データを作成すること自体は可能なので、ここから独自辞書を作成してみましょう。
独自辞書データ作成のためのセットアップ
独自辞書の登録にあたり、日本語入力を可能にするためのプログラムをインストールします。
ターミナル上で以下のコマンドを実行してください。
sudo apt-get install fcitx-mozc
 登録に必要なプログラムをインストール
登録に必要なプログラムをインストール
インストールが完了したら、Raspberry piを再起動して設定を反映させます。
再起動できたら、mozcがインストールできたか確認します。
上部メニューの部分にキーボードのマークが新たに追加されたことを確認してください。
 キーボードアイコンの確認
キーボードアイコンの確認
この時点では日本語入力ができませんが、先ほど表示されたキーボードアイコンをクリックするか、「ctr」キー+「スペース」キーを押すと、キーボードがオレンジ色の丸いアイコンに変わり、日本語入力ができるようになります。
 アイコンが変化して日本語入力が可能になる
アイコンが変化して日本語入力が可能になる
また上部メニューにmozcがインストールされると新しい項目が増えて設定することができるようになります。
 設定メニューに追加される
設定メニューに追加される
独自辞書に必要なファイルの作成
独自辞書データを作成するためには、「読み」「音素」「構文」「語彙」という4つの要素に対応するファイルが必要となります。それぞれ
- 「読み」ファイル —(hello.yomi)
- 「音素」ファイル —(hello.phone)
- 「構文」ファイル —(hello.grammar)
- 「語彙」ファイル —(hello.voca)
として作成します。
今回はファイルを管理しやすくするために、上記のファイルを「/julius/」ディレクトリー上の子ディレクトリ内に作成します。今回はディレクトリ名を「dict」とします。
「/julius/」ディレクトリ上で、次のコマンドを実行します。
mkdir dict
 「dict」ディレクトリーの作成
「dict」ディレクトリーの作成
作成した「dict」ディレクトリに移動して、ファイルを作成します。
cd dict/
 「dict」ディレクトリーに移動
「dict」ディレクトリーに移動
まず、「読み」ファイル(hello.yomi)から作成していきましょう。辞書に登録したい言葉の「読み」の情報を定義したファイルを作成します。
sudo vim hello.yomi
」ファイルの作成") 「読み(hello.yomi)」ファイルの作成
「読み(hello.yomi)」ファイルの作成
まず、左側に認識させたい言葉を書き、その右側に読み方をひらがなで記載してください。左側の言葉は、漢字で定義しても構いません。今回はシンブルに「おはよう」と「こんにちは」を定義しました。
おはよう おはよう こんにちは こんにちわ
」ファイルの中身") 「読み(hello.yomi)」ファイルの中身
「読み(hello.yomi)」ファイルの中身
続いて、「音素」ファイル(hello.phone)を作成します。「音素」ファイルは「julius」ディレクトリの中にあるスクリプト(yomi2voca.pl)を使って、「読み」ファイルから「音素」ファイルを作成します。
下のコマンドを入力して実行します。
iconv -f utf8 -t eucjp ~/julius/dict/hello.yomi | ~/julius/julius-4.4.2.1/gramtools/yomi2voca/yomi2voca.pl | iconv -f eucjp -t utf8 > ~/julius/dict/hello.phone
」ファイルから「音素(hello.phone)」ファイルを作成") 「読み(hello.yomi)」ファイルから「音素(hello.phone)」ファイルを作成
「読み(hello.yomi)」ファイルから「音素(hello.phone)」ファイルを作成
Juliusの仕様上、音素ファイルを作成するときに文字コードをUTF8からEUC-JPに変更する必要があります。上記のコマンドは、文字コードを変換してコマンドの最後に書いてある「hello.phone」ファイルに保存するための処理です。
作成した音素ファイルの内容は、下図のようになります。
 コマンドで文字コードをへん変換する
コマンドで文字コードをへん変換する
続いて、「構文」(hello.grammar)ファイルを作成します。「構文」ファイルは、認識する文章の構成を定義したファイルになります。
ターミナル上で以下のコマンドを実行します。
sudo vim hello.grammar
先ほど生成された「hello.phone」ファイルを参照して、下記のコードを記載します。
S : NS_B HELLO NS_E HELLO OHAYOU HELLO KONNICHIWA
」ファイルを作成")
構文ファイル1行目のSの部分は、構文定義を示し、NS_Bが文章の開始、NS_Eが文章の終了を表します。
2行目以下のHELLOの部分は認識させる文字列となっていて、先ほど生成された「音素」ファイル(hello.phone)の読みを大文字にして使います。
最後に、Juliusに認識させたい言葉を定義する「語彙」ファイル(hello.voca)を作成します。
ターミナル上で、以下のコマンドを実行してください。
sudo cp hello.phone hello.voca
ファイルを編集していきます。下記のコマンドを実行してください。
sudo vim hello.voca
Vimエディタが開くので、そのファイルに先ほど生成された「音素」ファイルをコピーしてペーストし、コピーした文字列を元に下記のように記載します。
※このとき、コピー&ペーストした音素ファイル文字列の区切りがタブになっているので、スペースに書き直してください。
% OHAYOU おはよう o h a y o u % KONNICHIWA こんにちは k o N n i ch i w a % NS_B [s] silB % NS_E [/s] silE
」ファイルの作成") 「語彙(hello.voca)」ファイルの作成
「語彙(hello.voca)」ファイルの作成
独自辞書データに変換
必要なファイルを作成することができたので、いよいよ辞書ファイルに変換します。
ターミナル上で、以下のコマンドを実行してください。
cd ~/julius/julius-4.4.2.1/gramtools/mkdfa
 「mkdfa」があるディレクトリーに移動換
「mkdfa」があるディレクトリーに移動換
このディレクトリーに移動できたことを確認して、下記のコマンドを実行します。
mkdfa.pl ~/julius/dict/hello
 独自辞書データに変換
独自辞書データに変換
成功すると、~/julius/dictファイル内に「.dfa」「.term」「.dict」ファイルが生成されます。
これで独自辞書を作成することができました。
 ファイルが作成されたことの確認
ファイルが作成されたことの確認
この独自辞書を使って、音声認識を行ないます。ターミナル上で、下記のコマンドを実行します。
julius -C ~/julius/julius-kit/dictation-kit-v4.4/am-gmm.jconf -nostrip -gram ~/julius/dict/hello -input mic
 独自辞書を使って、音声認識を開始する
独自辞書を使って、音声認識を開始する
「<<< please speak >>>」という表示中に音声認識が実行されます。
 音声認識が実行される
音声認識が実行される
何か話しかけてみると、結果を返してくれますが、「おはよう」と「こんにちは」だけしか表示されません。
今回作成した辞書に登録されている言葉が「おはよう」と「こんにちは」だけなので、今は他の言葉を話しても、「おはよう」か「こんにちは」のどちらかとして認識してしまいます。辞書データに認識させたい言葉を追加することで、他の言葉も認識できるようになります。
 「おはよう」か「こんにちは」のどちらかしか表示されない
「おはよう」か「こんにちは」のどちらかしか表示されない
独自辞書データの作り込みで、Raspberry Piでの音声認識精度は上げられる
ここまでRaspberry PiとJuliusでの音声認識の方法について、ご紹介してきました。
先にも書いたとおり、辞書データを作り込むことによって音声認識の精度を上げることができますが、限られた単語数でも、特定の言葉を認識させて動作するような使い方であれば、充分実用可能なレベルまで調整できると思います。
別の機会に、実際に言葉を認識させた上で動作する実践的プログラムをご紹介したいと思います。
[ネクスマグ] 編集部
パソコンでできるこんなことやあんなこと、便利な使い方など、様々なパソコン活用方法が「わかる!」「みつかる!」記事を書いています。