最近様々な場面で耳にする機会が多い「ディープラーニング」ですが、主な用途のひとつとして、似ているけれど異なるものを判別する、というものがあります。今回は最近ネットニュース等でも話題になっている東京の地名「青海」と「青梅」をディープラーニングで分類してみます。
文字で見ると非常に似ている「青海」と「青梅」。しかし地理的に言えば、その違いは歴然。直線距離で50km以上も離れており、電車で移動すれば2時間ほどかかります。ディープラーニングによって、「青海駅」と「青梅駅」を間違える人が減るかも…?
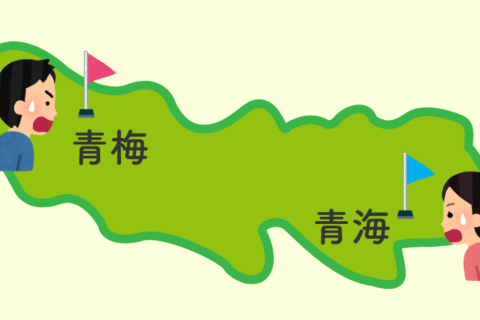
 文字は似ていても50km以上離れている「青梅」と「青海」
文字は似ていても50km以上離れている「青梅」と「青海」
RNN(再帰型ニューラルネットワーク)で「青梅」と「青海」を学習
今回の実験の流れのイメージは下記の通りです。
 集めた学習データで分類器を生成してテスト
集めた学習データで分類器を生成してテスト
学習データを集め、分類器を生成し、新しいテキストを用いてテストを行います。分類に使うアルゴリズムは、「ニューラルネットワークを使ってLINEの相手が「おじさん」か「女の子」か見破ってみた( https://www.pc-koubou.jp/magazine/1175 )」という記事でも利用したRNNと呼ばれるディープラーニングの手法です。RNNは文章や音声など連続性のある時系列データを扱うことができます。
また、前回の記事でもあったように、RNNは一般的に学習にとても時間がかかってしまうというのが問題点です。そこで、今回はGPUを利用してどれくらい時間を短縮して、学習が行えるのかの処理速度比較実験も一緒にしていきたいと思います。
▼ 今回使用するマシンのスペック
CPU:Intel Core i7-4790 3.60GHz
メモリ:8GB
グラフィックカード:NVIDIA GeForce GTX 980
「青梅」or「青海」分類器を生成する
学習データの準備
Twitterから約1500件ずつ取得した「青梅」と「青海」を含むツイートを学習データとして使用します。学習データはツイートごとに文末にラベルづけをする必要があります。今回は「青梅」をラベル:0、「青海」をラベル:1として、下記のようにテキストファイルに保存しました。
▼ 「青梅」(ラベル:0)の学習データの一部
昨日青梅線が鹿と衝突してたせいでめっちゃ遅刻したんだけど,0 青梅線に念願の特急!,0 今日青梅駅まで行ってたら凍死していた自信がある,0 青梅駅まで来たのは初めてやけど、のどかで良いとこやね,0
▼ 「青海」(ラベル:1)の学習データの一部
もしかしてzeppファイナルの帰りに青海駅を教えてくれた方?,1 青海駅はいっそのこと、森ビルがネーミングライツ買い取ってビーナスフォート前駅って名前にでもしたら良いと思ったり,1 青海のロッカーが埋まってるんだよね,1 次のコミケも企業行き確定か……青海まで行かないとイカンのだっけ……,1
これらを一つのファイルにまとめて、実行コードと同じディレクトリに保存しておきます。
上記のように、「青梅」と「青海」を含むツイートを眺めただけでも、地理的な情報以外の違いがなんとなく分かります。

このような違いをうまく学習させることができれば、行き先が「青梅」か「青海」かを迷った時に、ディープラーニングでどちらの可能性が高いかを導き出すことができます。(※きちんと地図をみて場所を確認した方が早くて正確です)
RNNを使って学習させる
続いて、準備したデータを使って「青梅」と「青海」を学習させていきます。先にも記載した通り、今回はRCNNというアルゴリズムを使用します。コードは、Chainerで実装されたGitHubのRecurrent Conventinal NN Text Classification for chainer( https://github.com/knok/rcnn-text-classification )を利用します。
上記URLにアクセスし、「train.py」と「model.py」をダウンロードし、先ほど用意した学習データと同じディレクトリに保存してください。
また、今回使うコードはChainerで実装されているので、下記のようにコマンドプロントから、pipを利用してインストールする必要があります。
$ pip3 install chainer
これ以外にも不足しているライブラリがある場合は適宜インストールしてください。
そして、今回は処理時間の比較のために「train.py」の最下部にある
if __name__ == '__main__':
main()
#
という部分を下記のように少し書き換えます。
if __name__ == '__main__':
start = time.time()
main()
execution_time = time.time() - start
print("処理時間(sec): %d" % execution_time)
#
準備が整ったら、上記のREADMEにも記載がありますが、下記のコマンドで学習をスタートさせます。
$ python3 train.py train [学習データ]
CPUとGPUの処理時間を比較する
ここで、CPUとGPUで学習の処理時間の比較を行います。GitHubからダウンロードしたままの状態のコードはCPUで処理するパラメータ指定になっているので、GPUで学習を行うときはパラメータを変更します。
下記の「train.py」の15行目〜28行目の部分にある関数を見てください。
def argument():
parser = argparse.ArgumentParser()
parser.add_argument('mode')
parser.add_argument('file')
parser.add_argument('--embed', default=200, type=int)
parser.add_argument('--vocab', default=3000, type=int)
parser.add_argument('--hidden', default=1000, type=int)
parser.add_argument('--epoch', default=10, type=int)
parser.add_argument('--model', default="model")
parser.add_argument('--classes', default=2, type=int)
parser.add_argument('--use-gpu', action='store_true', default=False)
parser.add_argument('--unchain', action='store_true', default=False)
args = parser.parse_args()
return args
25行目にある「parser.add_argument(‘–use-gpu’, action=’store_true’, default=False)」を「arser.add_argument(‘–use-gpu’, action=’store_true’, default=True」と変更します。
これで、GPUを使用して学習を行うことができます。
CPUとGPUの処理時間の比較結果
今回はエポック数(一つの訓練データを何回繰り返して学習させるか)を10エポックに設定して、それぞれ比較してみました。
エポック数を変更する場合は、先ほどと同様の「train.py」の15行目〜28行目の部分にある関数の22行目にある「parser.add_argument(‘–epoch’, default=10, type=int)」の「default=」の値を変更してください。
▼ 結果
| CPU | GPU | |
|---|---|---|
| 10エポック | 学習時間 4時間49分43秒 (17383秒) |
学習時間 1時間30分24秒 (5424秒) |
GPUを使用した学習時間はCPUの1/3以下の時間になりました!
学習回数を増やすとさらに差が広がると思われるので、今後ぜひ100エポックにも挑戦したいと思います!
「青梅」と「青海」を見分けてみた
処理速度の比較を行いながら、分類器の生成ができたところで、実際に「青梅」と「青海」を正しく分類できるかをテストします。
「青梅」と「青海」に行くシチュエーションを想定し、下記のように「青梅」と「青海」でできることを3つずつ挙げてみました。
▼ 「青梅」でできること
① 温泉に入る ② 昭和レトロな街並みを歩く ③ カフェ巡りをする
▼ 「青海」でできること
① アイドルのライブに行く ② ガンダムと写真を撮る ③ ショッピングモールで買い物をする
このテキストを使ってテストを行なってみたいと思います。
テストを行う場合は、下記のコマンドを実行します。
$ python3 train.py eval "テキスト"
テスト結果は下記のように出力されます。
''') # NOQA hyp: 0
「hyp:0」であれば「青梅」、「hyp:1」であれば「青海」という判定結果になります。
▼「青梅」のテスト結果
| テキスト | 結果 |
|---|---|
| ① 温泉に入る | 青海 |
| ② 昭和レトロな街並みを歩く | 青梅 |
| ③ カフェ巡りをする | 青梅 |
▼「青海」のテスト結果
| テキスト | 結果 |
|---|---|
| ① アイドルのライブに行く | 青海 |
| ② ガンダムと写真を撮る | 青海 |
| ③ ショッピングモールで買い物をする | 青梅 |
「青梅」で「温泉に入る」というメッセージ以外は見事正解という結果になりました!
まとめ
今回の実験により、ニュースで話題になるほど紛らわしい地名の「青梅」と「青海」を見分けることができました。ディープラーニングを用いることで純粋な地理的な情報以外にも「どんな目的でその場所に行くのか」というような部分も学習させることができたのではないかと思います。
また、GPUを使用して学習をすることで、大幅に処理時間が短縮されることもわかりました。データ量が多い場合、時間がかかる処理を行う場合はGPUを活用して処理を行っていきたいと思います。

工学部女子大生とライターをしています。卒業研究で彼氏の浮気を防ぐためにSNS上で彼氏と彼氏のフォロワーの親密度推定に挑戦中。大学院では計量言語学を専攻予定。