個人も企業もSNSを活用して情報を発信するのが当たり前の時代となり、どんな投稿を行えば多くの人の目に留まるだろうか?と試行錯誤している人は少なくありません。 SNS分析アプリなども増えてきていますが、今回はTwitter上にある自分の過去のツイートをPythonで分析し、どんなツイートが「いいね」されやすいかを調べてみようと思います。
データの準備
まず、Twitterアナリティクスから自分の過去のツイートデータを取得します。
“ Twitterアナリティクス”.2019.Twitter, Inc.
https://analytics.twitter.com/
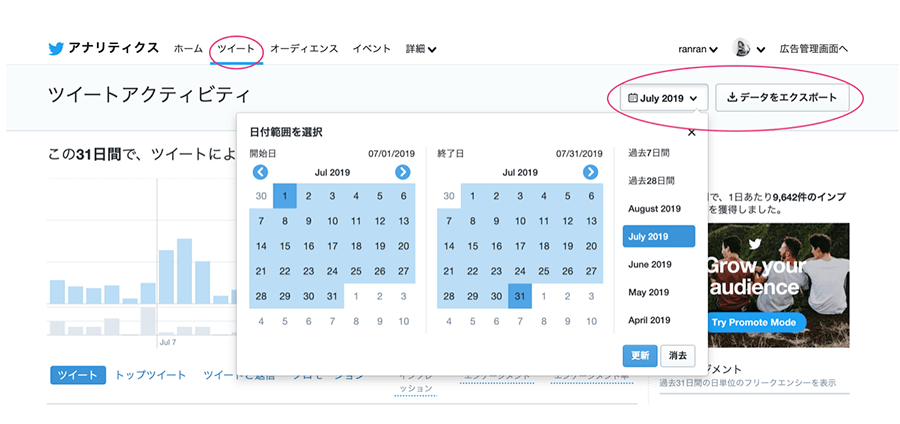
「ツイート」のページを開き、右上から期間を設定し、「データをエクスポート」をクリックするとツイートデータのダウンロードが始まります。データのダウンロードは1ヵ月ごとなので、期間をずらしながらダウンロードしてください。
今回は2019年4月〜2019年7月のデータをダウンロードし、以下のようにそれぞれ名前を付けて保存しました。
- apr.csv
- may.csv
- jun.csv
- jul.csv
ここからPythonを使い、分析を始める準備をします。
環境構築の方法については下記の記事を参考にしてください。
“Python Windowsで開発環境の構築”
https://www.pc-koubou.jp/magazine/4188
以下が今回使用するライブラリです。
- pandas
- numpy
- matplotlib
- seaborn
- collections
- nagisa
コマンドプロンプトを開き、インストールしたことがないライブラリがあれば、下記のコマンドでインストールを行なってください。
pip install [ライブラリー名]
続いて、Python各CSVファイルを読み込み、結合させ、分析に必要なデータ(ツイート本文、いいね、リツイート、時間)を取り出します。
# -*- coding: utf-8 -*- import pandas as pd #CSVを読み込む apr_df = pd.read_csv(“apr.csv”) may_df = pd.read_csv(“may.csv”) jun_df = pd.read_csv(“jun.csv”) jul_df = pd.read_csv(“jul.csv”) #結合させる combine = [april_df, may_df, june_df, july_df] #データフレームを作成し、いいねが多い順に並べる tweets_df = tweets_df = pd.concat(combine) .sort_values(by=“いいね”, ascending=False) #分析に必要なデータのみを取り出す tweets_df = tweets_df[[“ツイート本文”, “リツイート”, “時間”, “いいね”]]
以上で、データの準備は完了です。
データ分析&グラフ化
ここからPandasのPlot機能とMatplotlibを使って、データの分析とグラフの作成を行います。
今回、形態素解析を行うためのライブラリとしてnagisaを使用します。(nagisaについては後ほど説明します。)
# -*- coding: utf-8 -*-
#データの扱うためのライブラリを読み込む
import pandas as pd
import numpy as np
import nagisa
from collections import Counter
#グラフ化を行うためのライブラリを読み込む
import matplotlib
import matplotlib.pyplot as plt
#Matplotlibのグラフスタイルの設定
plt.style.use(“seaborn-pastel”)
font = {“family” : “IPAexGothic”}
matplotlib.rc(“font”, **font)
上記のMatplotlibのグラフスタイルの設定では、統計データビジュアライゼーションライブラリのseabornを使うことで簡単にグラフの色合いなどを変更することができます。どのようなスタイルを利用することができるかは下記の記事を参考にしました。
“matplotlibのstyleを変える”.2019.Increments Inc.
https://qiita.com/eriksoon/items/b93030ba4dc686ecfbba
現状、どのくらい「いいね」されてる?
これでグラフを作成する準備が整ったので、まずはいいね数ごとのツイート件数の分布がわかるヒストグラムを作成します。
#グラフを描写 tweets_df.plot.hist( y=[“いいね”], bins=50, figsize=(16,9)) #グラフを保存 plt.savefig(“ヒストグラム.png”)
▼いいね数ごとのツイート件数の分布がわかるヒストグラム
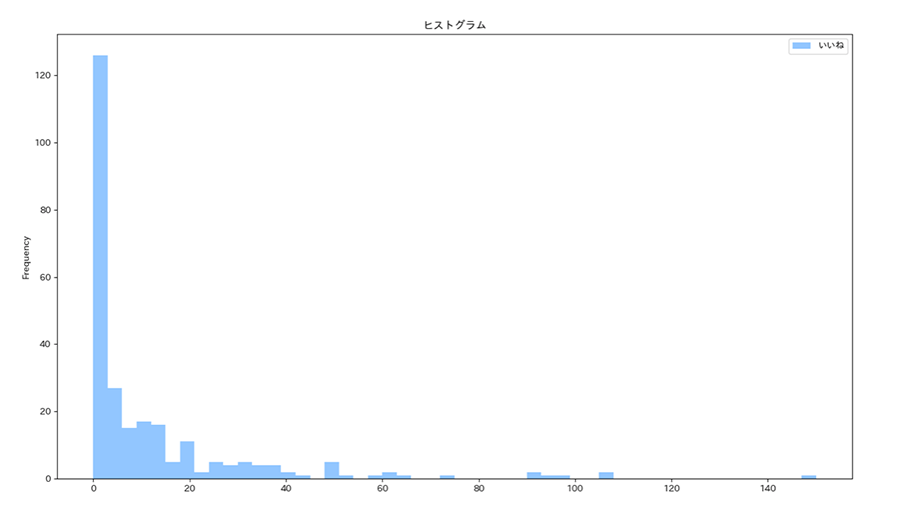
このヒストグラムを見ると、まず圧倒的にいいね数が0〜20くらいのツイートが圧倒的に多く、それ以上のいいね数のツイートはまだまだ少ないということがわかります。もちろん、SNSを利用する上でいいね数だけが重要なわけではありませんが、今回の分析結果をもとにもっとうまくTwitterを活用できるようになれたらいいなと思います!
「いいね」されやすい時間帯は?
続いて、時刻別平均いいね数とツイート数のグラフを作成します。平均いいね数は棒グラフ、ツイート数は折れ線グラフで描写します。
#時間データから日付や分数を取り除く tweets_df[“時間”] = pd.to_datetime(tweets_df[“時間”]) tweets_df[“時刻”] = tweets_df[“時間”].dt.hour #いいね数と時刻のデータフレームを作成 time_df = tweets_df[[“いいね”,”時刻”]] #時刻順に並び替える time_df = time_df.sort_values(by=[“時刻”], ascending=True) #時刻ごとにデータを集計 grouped = time_df.groupby(“時刻”) #時刻ごとの平均いいね数 mean = grouped.mean() #時刻ごとのツイート数 size = grouped.size() #時刻ごとの平均いいね数の棒グラフを描写 mean.plot.bar(xlim=[0,24], ylim=[0,40],figsize=(16,9)) #時刻ごとのツイート数の折れ線グラフを描写 size.plot.bar(xlim=[0,24], ylim=[0,40],figsize=(16,9)) #描写したグラフを保存 plt.savefig(“時刻別平均いいね数とツイート数.png”)
▼時刻別平均いいね数とツイート数
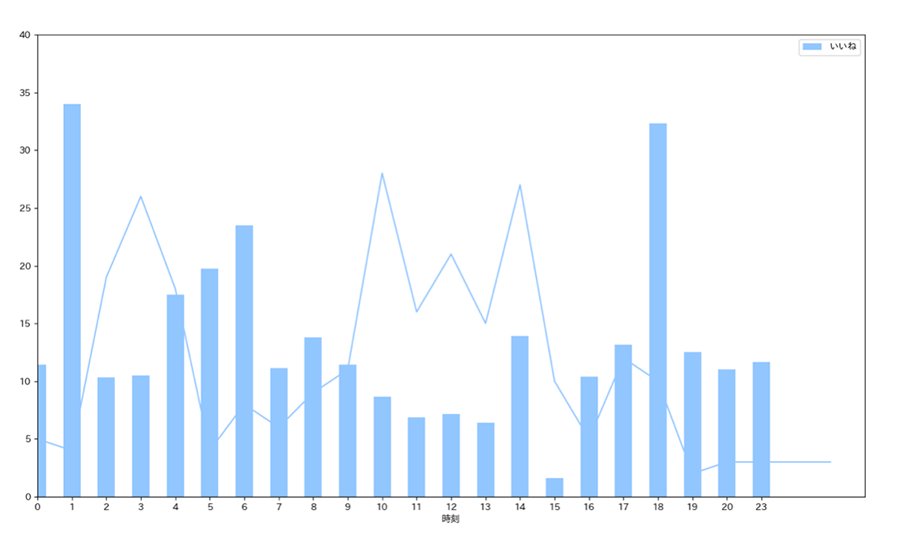
グラフを見ると、ツイート数は3時、10時、14時となっており、就寝前とお昼ご飯の前後でツイートすることが多いことがわかります。しかし、平均いいね数が多いのは1時、18時となっているので、この時間帯を狙ってツイートすると、「いいね」をしてもらえる可能性が増えるかもしれません。
「いいね」されやすい文字数は?
次に「いいね」が多いツイートと少ないツイートで文字数に違いがあるのかを分析します。
今回は、以下の基準でツイートに評価を付け、各評価のツイートの平均文字数を算出し、棒グラフにしました。
| いいね数 | 評価 |
|---|---|
| 50以上 | A |
| 30以上50未満 | B |
| 20以上30未満 | B |
| 10以上20未満 | D |
| 10未満 | E |
#評価付け
tweets_df.loc[tweets_df[“いいね”] >= 50, “いいね評価”] = “A”
tweets_df.loc[(tweets_df[“いいね”] < 50) & (tweets_df[“いいね”] >= 30), “いいね評価”] = “B”
tweets_df.loc[(tweets_df[“いいね”] < 30) & (tweets_df[“いいね”] >= 20), “いいね評価”] = “C”
tweets_df.loc[(tweets_df[“いいね”] < 20) & (tweets_df[“いいね”] >= 10), “いいね評価”] = “D”
tweets_df.loc[tweets_df[“いいね”] < 10, “いいね評価”] = “E”
#各ツイートの文字数を取得
tweets_df[“文字数”] = tweets_df.ツイート本文.str.len()
#評価用リストを作成
hyoka = [“A”, “B”, “C”, “D”, “E”]
#評価ごとの平均文字数を格納するデータフレームを作成
fav_mean_df = pd.DataFrame(index = hyoka, columns = [“平均文字数”])
#作成したデータフレームに平均文字数を格納
for i in hyoka:
df = tweets_df[tweets_df.いいね評価 == i]
fav_mean_df.loc[[i],[“平均文字数”]] = df[“文字数”].mean()
#グラフを描写
fav_mean_df.plot.bar(figsize=(16,9))
#描写したグラフを保存
plt.savefig(“いいね評価ごとの平均文字数.png”)
▼いいね評価ごとの平均文字数
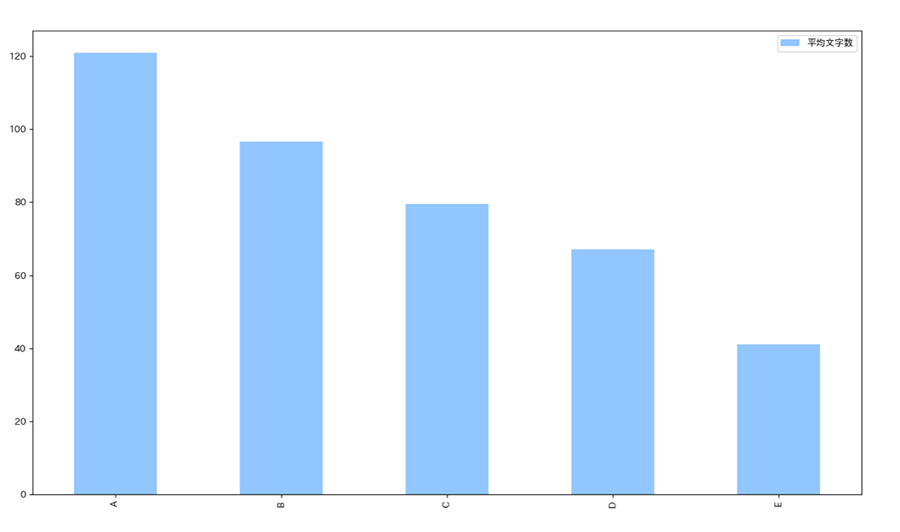
いいね評価ごとの平均文字数はかなり分かりやすい結果となりました。いいね数が多い評価Aのツイートは平均文字数が120文字程度で、評価が下がるごとに平均文字数は減っていき、評価Eでは平均文字数が40文字程度となっています。文字数は多ければ多いほど、「いいね」されやすいということが分かります。
どんな単語を使っているツイートが「いいね」されやすい?
先ほどの評価ごとに出現回数が多い単語を調べてグラフにします。
出現回数が多い単語を調べるために、ツイート本文を形態素解析し、各単語の出現回数をカウントします。冒頭でも少し触れましたが、今回は形態素解析に「nagisa」というライブラリを使用します。
「nagisa」ではBidirectional-LSTM を用いた日本語単語分割と品詞推定を行うため、顔文字やURL、ネット用語などにも対応することができます。「Mecab」などと比べると解析速度が遅い点が短所ではありますが、今回はデータ量も多くないので問題なく利用できそうです。
#評価ごとに順番に単語の出現回数をカウントし、グラフ化する
for i in hyoka:
#対象の評価のツイートデータを抽出したデータフレームを作成
df = tweets_df[tweets_df.いいね評価 == i]
#単語を格納するリストを作成
word = []
#ツイート本文をnagisaで形態素解析する
for text in df[“ツイート本文”]:
#改行コードを削除
text = text.replace(“\n”, ““)
#品詞が助詞・助動詞・補助記号・空白以外のものを形態素解析
words = nagisa.filter(text, filter_postags=[“助詞”, “助動詞”,”補助記号”,”空白”])
#単語を抽出し、リストに追加
word.extend(words.words)
#各単語の出現回数をカウントする
c = Counter(word)
#出現回数が多い単語30個を抽出しデータフレームを作成
count_df = pd.DataFrame(c.most_common(30), columns = [“単語”,”出現回数”])
#単語の列をインデックスに設定
count_df = count_df.set_index(“単語”)
#出現回数が多い順に並び替える
count_df = count_df.sort_values(by=“出現回数”, ascending=True)
#グラフを描写
count_df.plot.barh(y=“出現回数”, figsize=(10,10))
#グラフを保存する
plt.savefig(“出現回数の多い単語(評価:%s).png” % i)
▼出現回数の多い単語
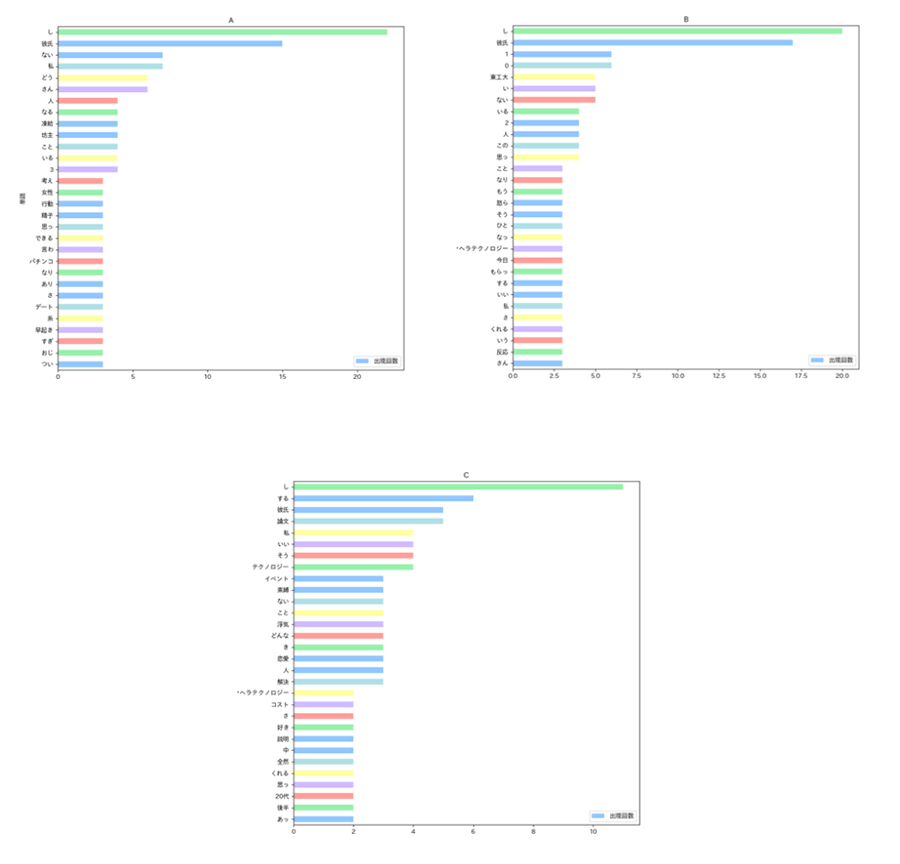
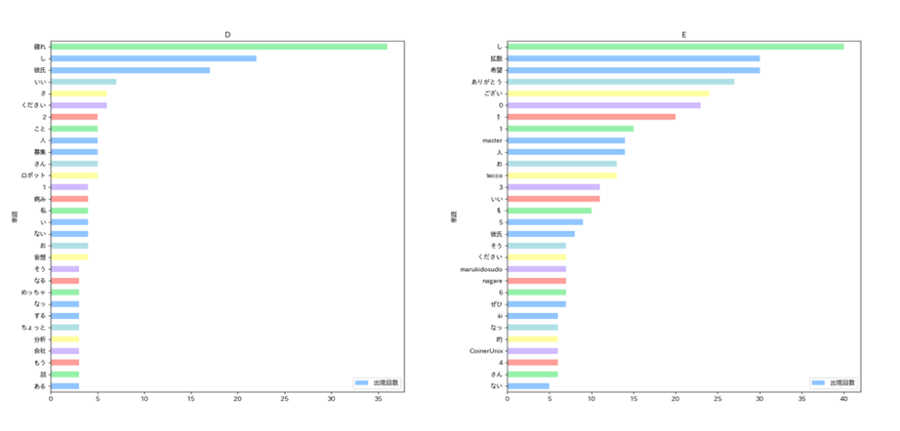
評価ごとの出現回数が多い単語を見ていくと、特徴的なのはAからCまでは動詞の「し」「する」の次に「彼氏」が多いですが、Dになると「寝れ」が最も多くなり、Eについては17番目とかなり下位となっています。この結果を見ると、私の場合は「彼氏」に関するツイートをすると「いいね」されやすいということが言えそうです。
「彼氏」を含むツイートが「いいね」されやすい?
出現回数が多い単語の分析結果を受け、「彼氏」を含むツイートと含まないツイートで「いいね」の数が異なっているかも調べてみました。
まず、「彼氏」を含むツイートと含まないツイートの数を出し、グラフにしました。
#ツイート本文から「彼氏」を含むツイートを抽出
tweets_df["彼氏ツイート"] = tweets_df.ツイート本文.str.contains("彼氏")
#グラフを描写
tweets_df["彼氏ツイート"].value_counts().plot.bar()
#グラフを保存する
plt.savefig('彼氏を含む/含まないツイート数.png')
▼彼氏を含む/含まないツイート数
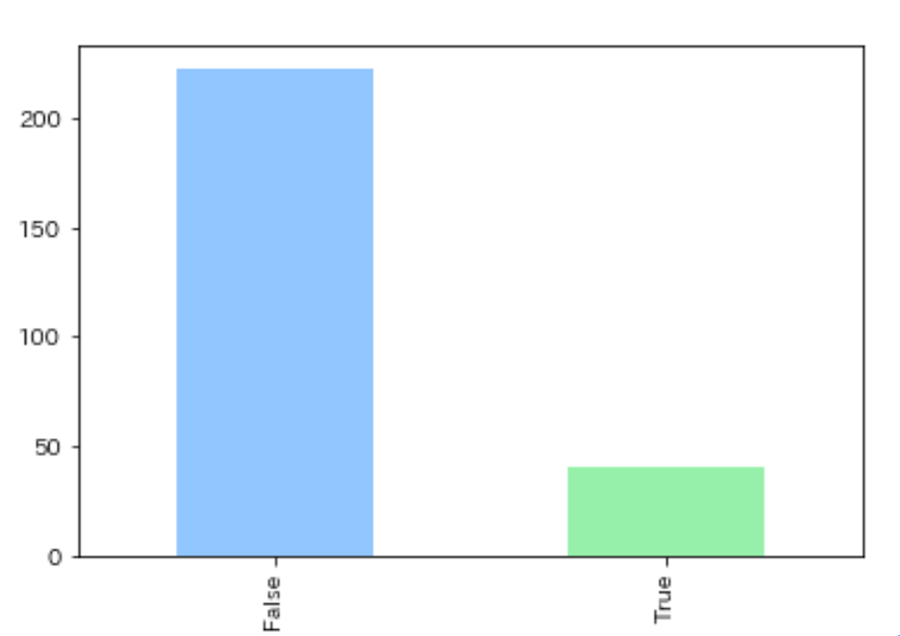
Trueが「彼氏」を含むツイート、Falseが「彼氏」を含まないツイートの数になっています。「彼氏」を含むツイートは全体の15%ほどでした。
続いて、「彼氏」を含むツイートと含まないツイートのそれぞれの平均いいね数を出し、グラフにします。
#「彼氏」を含むツイートの平均いいね数を取得
df = tweets_df[tweets_df.彼氏ツイート == True]
y1 = df["いいね"].mean()
#「彼氏」を含まないツイートの平均いいね数を取得
df = tweets_df[tweets_df.彼氏ツイート == False]
y2 = df["いいね"].mean()
#各値をリスト化
x = ["含む", "含まない"]
y = [y1, y2]
#グラフを描写
plt.bar(x, y)
#グラフを保存
plt.savefig('彼氏を含む/含まないツイートの平均いいね数.png')
▼彼氏を含む/含まないツイートの平均いいね数
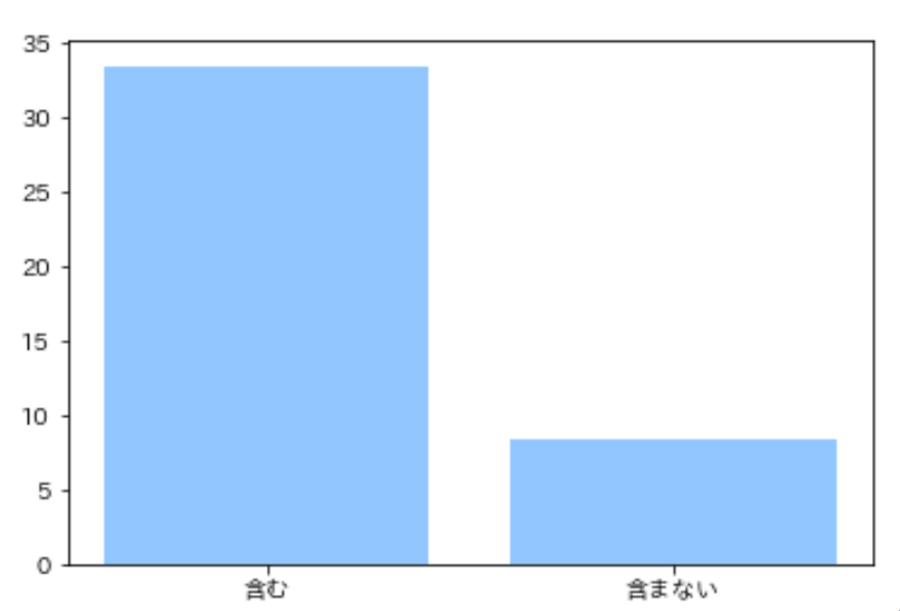
なんと「彼氏」を含むツイートの平均いいね数は含まないツイートの約4倍という結果に!
私自身、感覚的になんとなく彼氏に関するツイートは「いいね」がつきやすい印象はありましたが、彼氏以外のツイートとの差が4倍もあるとは思わなかったので、非常に驚きました。
まとめ

今回、Pythonを使った分析を行ってみて、私のツイートに関しては以下のようなことが分かりました。
- いいね」されやすい時間帯は午前1時と午後6時
- 文字数は多ければ多いほど、「いいね」されやすい
- 「彼氏」を含むツイートは含まないツイートの4倍「いいね」されやすい
ネット上には多くの人に当てはまるテクニックなども多く紹介されていますが、今回のように自分のツイートに特化した分析はとても面白く、役に立ちそうだと感じました。
また、今回は「いいね」を基準に分析を行ってみましたが、他にもリツイートやインプレッション、エンゲージメント、フォロワー増加数などいろいろな基準で分析することができるので、ぜひ今後ほかの指標でも分析を行ってみたいと思いました。

工学部女子大生とライターをしています。卒業研究で彼氏の浮気を防ぐためにSNS上で彼氏と彼氏のフォロワーの親密度推定に挑戦中。大学院では計量言語学を専攻予定。