ショッピングサイトのレコメンド(おすすめ)機能の手法のひとつである協調フィルタリングについて、PythonでExcelデータを読み込んでフィルタリングを行う手順についてご紹介します。
協調フィルタリングとは
協調フィルタリングとは、ユーザーの行動履歴のような評価点を比較し、評価点の距離から似ているもの同士を割り出すレコメンドする手法です。
協調フィルタリングにはアイテム間の類似度を計算する「アイテムベース協調フィルタリング」とユーザー間の類似度を計算する「ユーザーベース協調フィルタリング」の二つに区別されます。
「アイテムベース協調フィルタリング」では、商品Aと良く一緒に購入される商品Bが存在する場合に、商品Aを購入した人に対して商品Bをおすすめします。
一方「ユーザーベース協調フィルタリング」では、Aさんが商品Aと商品Bと商品Cを購入していて、Bさんも商品Aと商品Bを購入しているような場合に、AさんとBさんは似ている行動をしていると捉え、Bさんも商品Cに興味があると推定します。
協調フィルタリングは様々なレコメンドシステムのベースとなっており広く活用されていますが、商品の販売データやユーザーの行動履歴データを基にするため、レコメンドの精度はデータの量に依存する面があります。
AnacondaでPython環境構築
今回はデータ分析や機械学習に必要なライブラリーが最初から入っている「Anaconda」を使用してPythonの環境を構築します。
まずAnaconda の公式ホームページにアクセスして、「Python 3.x version」の「Download」ボタンをクリックしてダウンロードを開始します。
“Anaconda Python/R Distribution – Anaconda”.2019.Anaconda.
https://www.anaconda.com/distribution/#download-section
Windows版をダウンロードします。
 windows版を選択してダウンロードする
windows版を選択してダウンロードする
ダウンロードが完了したら.exeファイルをクリックして起動します。
すると、Anacondaの初期画面が開くので、「Next」ボタンをクリックして次の画面に進みます。
 Anacondaの初期画面
Anacondaの初期画面
ライセンスの確認画面が表示されるので、ライセンスを確認したら「I Agree」ボタンをクリックして次の画面に進みます。
 ライセンスを確認して次へ進む
ライセンスを確認して次へ進む
次の画面はユーザーとしてインストールするか、コンピュータにインストールするか選択する画面が表示されるので、「Just Me」を選択して「Next」ボタンをクリックする。
 「just me」にチェックが入っているか確認する
「just me」にチェックが入っているか確認する
インストール先を選択する画面が表示されるので、特に設定することもないのでこのまま「Next」をクリックして次の画面に進みます。
 変更する場合は「Browse」をクリック
変更する場合は「Browse」をクリック
この画面は、インストールの際に「環境PATHにAnacondaのフォルダーを追加する」という項目になるのですが非推奨なので、このまま項目を変更しないで「Install」をクリックしてインストールを開始します
 上の項目にチェックが入っていないことを確認する
上の項目にチェックが入っていないことを確認する
下図の画面になるので「Finish」ボタンをクリックしてウインドウ画面を閉じます。
 「Finish」を押してインストールを完了する
「Finish」を押してインストールを完了する
これでAnacondaのインストールは完了です。
次にAnacondaの環境が構築できたのかを確認します。
左下のWindowsボタンを押して、windowsメニューを開いて「Anaconda3」というファイルを見つけてその中に同封してある「Anaconda Prompt」を選択して実行します。
 「Anaconda3」ディレクトリーの中に入っている
「Anaconda3」ディレクトリーの中に入っている
実行すると、黒いウインドウが開きます。
ここからは、この「Anaconda Prompt」内で作業を始めます。試しに下記のコマンドを実行してPythonバージョンを確認してみます。
python -V
 コマンドの「V」は大文字で実行する
コマンドの「V」は大文字で実行する
ちなみに、windows標準の「コマンドプロンプト」で同じコマンドを実行してもPythonは動作しません。
 似ている画面のため確認する
似ている画面のため確認する
とても似ている画面なので間違いそうですが、見分け方としてはウインドウ左上の表示を見ると名所が違うのでpythonの環境が表示されない時はこの部分を確認します。
これでAnacondaの環境が整いました。次は実際にデータとプログラムを用意して協調フィルタリングを実装してみます。
データの用意
協調フィルタリングは、それぞれの人の評価点の距離を比較する手法になっているので、協調フィルタリングのデータについては、モノに対して人の行動や評価を数値化した表をデータとします。
このデータは具体的には何段階評価や買った買わないなどを0と1で表したり、数字に置き換えることができれば、どんなものでもデータとして使用することができます。
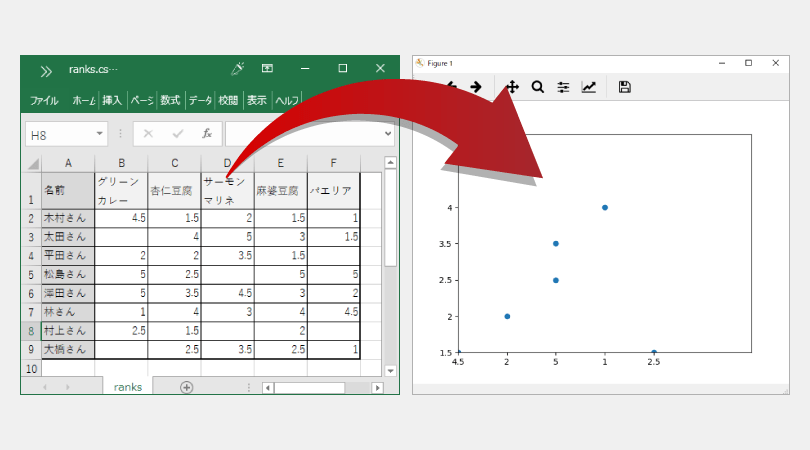
ただ0と1の2段階より、ある程度の段階がある方が精度が良くなるので今回は8人を対象にそれぞれの料理がどの程度好みなのかを「10段階評価」で数値を出して表にまとめたデータを用意しました。
 ranks.csvの中身
ranks.csvの中身
なお今回のデータのファイル名は「ranks.csv」としました。
Pythonプログラムの用意
データを用意することができたので、次に実際Pythonのプログラムを書いていきます。
最初は、csvファイルのデータをグラフに表示させてみます。
csvファイルのデータをグラフに表示させる
今回は作業ディレクトリーを作成してその中にプログラムと作成したデータを同一ディレクトリーで管理したと思います。
下記のコマンドを入力して実行してディレクトリーを作成します。
mkdir filter
 「filter」ディレクトリーを作成
「filter」ディレクトリーを作成
作成したディレクトリーに移動します。
cd filter
 「filter」ディレクトリーに移動
「filter」ディレクトリーに移動
下記のコマンドで空のPythonファイルを作成します。
今回は「sample_csv.py」というファイル名にしました。
type nul > sample_csv.py
 空のファイルが作成される
空のファイルが作成される
ファイルを作成したら、一旦今のディレクトリーの状態を確認します。
dirコマンドで現在いるディレクトリーの中身を確認することができます
dir
 linuxでの「ls」コマンドにあたる
linuxでの「ls」コマンドにあたる
csvデータからグラフを表示するために「matplotlib」ライブラリーを使います。
このライブラリーはPythonでグラフを描画することであったり、イメージを表示させる際に必要になるライブラリーでインポートすると使用できるようになります。
Anacondaではインストールをすると自動的に「matplotlib」ライブラリーも導入してくれるので新しく入れる必要はないです。
好きなテキストエディタでファイルを開いて、下記のプログラムを書きファイルを保存してください。
from matplotlib import pyplot
import csv
def getData():
rows = []
f = open('ranks.csv', 'r')
reader = csv.reader(f)
for row in reader:
rows.append(row)
f.close()
return rows
rows = getData()
rows.pop(0)
xs = []
ys = []
for i in range(len(rows)):
x = rows[i][1] # グリーンカレー
y = rows[i][2] # 杏仁豆腐
if len(x) == 0 or len(y) == 0:
continue
xs.append(x)
ys.append(y)
print(xs)
print(ys)
pyplot.xlim(0, 6)
pyplot.ylim(0, 6)
pyplot.plot(xs, ys, 'o')
pyplot.show()
 sample_csv.pyのプログラム
sample_csv.pyのプログラム
比較として、今回は「グリーンカレー」と「杏仁豆腐」を比較対象にプログラムを設定しています。
プロフラムを動かすため下記のコマンドを入力します。
python sample_csv.py
 プログラムの実行
プログラムの実行
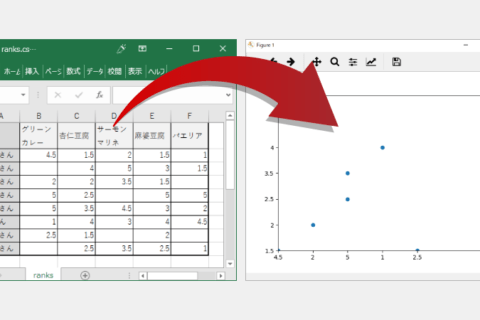
実行結果は下図になりました。
左の画面のコマンドプロンプト画面に表示されているのが、csvから取得してきたデータを示しており昇順に並んでいます。
右の画面は、取得したデータをグラフで表示している図になります。
グラフの表は、横軸は「グリーンカレー」を表し縦軸は「杏仁豆腐」を示しており、丸い青い点はユーザーを示しています。
例えば、今回のデータの「松島さん」のケースで説明すると、松島さんは横軸「グリーンカレー」は数値が5で縦軸「杏仁豆腐」は数値が2.5なので下図の部分が松島さんということになります。
 プログラム実行するとグラフが生成される
プログラム実行するとグラフが生成される
評点の距離を比較して類似度を割り出す
グラフにデータを表示することができたので、次にそれぞれの人の評点の距離を具体的な数値を出して類似度を比較してみます。
下記のコマンドを入力して「sample_score.py」ファイルを同じディレクトリー内に作成します。
type nul > sample_score.py
 sample_score.pyファイルの作成
sample_score.pyファイルの作成
ファイルを作成することができたら、好きなテキストエディタでファイルを開いて、下記のプログラムを書きファイルを保存してください。
from operator import itemgetter
from math import sqrt
import csv
def getData():
rows = []
f = open('ranks.csv', 'r')
reader = csv.reader(f)
for row in reader:
rows.append(row)
f.close()
return rows
def getSimDistance(data1, data2):
items1 = []
items2 = []
for i in range(len(data1)):
e1 = data1[i]
e2 = data2[i]
if len(e1) == 0 or len(e2) == 0:
continue
items1.append(float(e1))
items2.append(float(e2))
# ひとつも共通項がなかったら...
if len(items1) == 0:
return 0
sum = 0
for i in range(len(items1)):
sum += pow(items1[i] - items2[i], 2)
return 1/(1+sqrt(sum))
rows = getData()
rows.pop(0)
idx = 3 # 松島さん
user = rows[idx]
print(user[0], 'との類似度')
user.pop(0)
sims = {}
for i, e in enumerate(rows):
if i == idx:
continue
name = e[0]
e.pop(0)
sims[name] = getSimDistance(user, e)
# print(sims)
print(sorted(sims.items(), key=itemgetter(1), reverse=True))
 sample_score.pyのプログラム
sample_score.pyのプログラム
プログラムを動かすので、下記のコマンドを入力して実行させます。
python sample_score.py
 プログラムの実行
プログラムの実行
「松島さん」とそれぞれのユーザーを比較して類似度を数値化したのが下図の結果になります。
点と点との距離が近い人が類似しており、点と点との距離が遠い人は類似していないことを示すので、松島さんを基準としたケースの場合、一番類似しているのが点と点との距離が近い「澤田さん」となり、一番類似していないのが点と点との距離が遠い「木村さん」ということが数値化したことにより割り出しました
なので良くある「この商品を買った人は、こんな商品も…」のような機能では、「松島さん」が購入した商品は「澤田さん」にもおすすめがしやすくて、逆に「松島さん」が購入した商品は「木村さん」にはおすすめしにくいということになります。
 「松島さん」とそれぞれを比較して数値を出す
「松島さん」とそれぞれを比較して数値を出す
 評点との距離を測る
評点との距離を測る
Pythonで協調フィルタリングをしてみる
今回はPythonで協調フィルタリングを実装してみました。
商品をレコメンドする機能やアルゴリズムは、協調フィルタリングだけではなく他にも様々な手法があります。
それぞれの手法で長所や短所があるので、別の機会に他の手法についてもご紹介したいと思います。

石郷祐介
大学卒業後、公設研究機関勤務を経て、「情報科学芸術大学院大学[IAMAS]」に入学。
専門学校講師を経て、企業の研究開発をコンセプトから開発まで支援する「合同会社4D Pocket」代表、エンジニアを養成するフリースクール「一般社団法人HOPTER TECH SCHOOL」代表理事、「名古屋文理大学」及び「名古屋造形大学」非常勤講師。