Pythonの代表的な機械学習用のフレームワークである「scikit-learn(サイキットラーン)」で、「SVM(サポートベクターマシン)」を用いた基本的な機械学習の流れと手順についてご紹介します。
scikit-learnとは
scikit-learn(サイキットラーン)とは、Pythonの代表的な機械学習のオープンソースライブラリーで、難しいプログラムを実装することなく機械学習を試すことができ、初心者にも扱いやすいのが特徴です。
scikit-learnには多くの機械学習アルゴリズム(計算や処理の手順)が含まれていますが、どのアルゴリズムも同じような記述方法で使うことができるのも扱いやすい理由のひとつとなっています。
今回はscikit-learnに含まれるアルゴリズムのうち「SVM(サポートベクターマシン)」を使用してみたいと思います。
SVM(サポートベクターマシン)とは
SVM(サポートベクターマシン)とは、データを分類して境界線を引くためのアルゴリズムです。「教師あり学習」と呼ばれる手法を用い、正解データを「教師からの助言」として学習し、学習結果をもとに境界線を定めた「分類器」を作成します。
その分類器を活用して、新しいデータ(未知のデータ)を入力した時に、そのデータがどちらに分類されるかどうかを区別することができるようになります。
scikit-learn環境構築
今回環境構築はPythonのディストリビューション(設定済みファイルをまとめたもの)である「Anaconda」を使って環境構築を行います。
Anacondaにはscikit-learnだけでなく、今回scikit-learnの他に使用する下記ライブラリーのうち「NumPy」や「Matplotlib」も含まれています。
Anacondaのインストールについては下記記事を参照してください。
“PythonとExcelデータで協調フィルタリングを実装”
https://www.pc-koubou.jp/magazine/22437
今回scikit-learnの他に使用するライブラリーは下記の通りです。
●NumPy・・・数値計算ライブラリー、少ないコード量で計算することができる
●Matplotlib・・・様々なグラフ描画ができるライブラリー
●mlxtend・・・観測した結果などをグラフに描き入れる際に使うライブラリー
scikit-learnを使ってみる
scikit-learnには教師データとしてサンプルが既に用意されているので、それを最初に使ってみたいと思います。
サンプルは何種類か用意されていて、今回は「load_iris」花の種類であるアヤメのデータを学習させて、特徴量を与えると品種を予測できるか確認してみます。
まずは下記のコマンドを実行して今回の作業ディレクトリーを作成し、サンプルのデータを取得できるか確認してみます。
mkdir scikit
 新しいディレクトリーを作成
新しいディレクトリーを作成
作成したディレクトリーに移動します。
cd scikit
 作成したディレクトリーに移動
作成したディレクトリーに移動
新しくPythonのプログラムファイルを作成します。
type nul > sample_load.py
 新規ファイル作成
新規ファイル作成
作成した「sample_load.py」の中身を書きます。下記のコードを書いてください。
from sklearn.datasets import load_iris iris = load_iris() print (iris.data.shape) print (iris.target_names)
プログラムが書けたら下記コマンドで実行し、動作を確認します。
python sample_load.py
 プログラム実行
プログラム実行
サンプルのデータの中身を確認してみました。すると(150,4)という結果が表示されました。
これは、このサンプルデータの中にデータが150個あり、特徴量は4つであるということを示しています。
下図の’setosa’ ‘versicolor’ ‘virginica’ の部分は花の品種を示しています。
 データの確認
データの確認
次にサンプルデータの特徴量の中身を見てみたいので、先頭から120個のサンプルを出力してみます。
「sample_load.py」の最下部に追記で下記のコードを追加してください。
for data, target in zip(iris.data[:120], iris.target[:120]): print(data, target)
ざっと120個のサンプルを出してみました。[ ] 内に入っている値が特徴量を示しておりそれぞれ値が入っています。一番右の数値は先ほど出力した「花の品種」を表しています。
ここからランダムに一つデータを選んでそのデータの特徴量を与えて分類できるのかやってみます。
データはこの中にあるデータならどのデータでも構いませんので好きな値を選択してください。
今回はこのデータを選択しました。
[5.5, 2.6, 4.4, 1.2]
 選択したデータ
選択したデータ
次にプログラムを変更します。「sample_load.py」の中身を下記のコードに書き換えてください。
from sklearn import svm from sklearn.datasets import load_iris iris = load_iris() # 学習させる clf = svm.SVC(gamma="scale") clf.fit(iris.data, iris.target) # ランダムに見つけた値で分類できるかどうか確認する # case versicolor test_data = [[ 5.5, 2.6, 1.4, 0.2]] print(clf.predict(test_data))
結果が[1]と出力されているので、特徴量の数値のデータから[versicolor]だと分類することに成功しました。
簡単にプログラムの流れを説明すると、まず取得したサンプルデータをSVMで学習をするという指定を行い、
実際に学習を行う場合は.fit()の部分で行います。
ちなみにclfはclassficationの略語ですが、翻訳すると分類という意味です。
最後に、predictで予測させたいデータを指定して結果を出力するという流れになっています。
学習から予測まで、短いコードを書いてプログラムを実行するだけで実装ができました。
 数値から予測した結果
数値から予測した結果
実用性を考慮してscikit-learnを使用してみる
先ほどはscikit-learnで使用できるサンプルデータを使用して学習から予測までを試してみましたが、今度は実際にデータを作成して学習させ、予測をしてみます。
今回は実用性を考慮して工場や製作現場での「過去の良品・不良品の数値を読み込ませて、次にきた値から、良品・不良品のどちらかを推測する」というものを作成してみようと思います。
教師ありデータの作成
用意したデータは下記の通りです。データの一番左の列が「良品(0)」と「不良品(1)」を表しており、左から2番目と3番目の列については、検品の際の計測結果を想定した数値を入力しています。
それぞれの値はランダムに入力しており、計測結果の数値と良品/不良品の値に相関関係は持たせていません。
ファイルの名前は「data.csv」としました。
 data.csvの中身
data.csvの中身
今回のデータは冒頭でも説明した「教師あり」データになっており、「良品、不良品」の部分は正解ラベルとも言われています。データと正解ラベル、(正解or不正解)を読み込ませて、予測を行います。
ここでもうひとつ、今回比較したいデータをデータファイルとして作成して用意します。このデータの値も好きな値に設定して構いません。
このファイルの名前は「data_test.csv」にしました。
 data_test.csvの中身
data_test.csvの中身
ここで一度、現時点でのディレクトリーの中身を確認しておきます。
●sample_load.py・・・Pythonプログラム
●data.csv・・・学習させたい過去の良品・不良品の数値データ(.csv)
●data_test.csv・・・予測させたい数値データ(.csv)
 作業フォルダーの中身
作業フォルダーの中身
良品・不良品を推測するプログラム
新しくファイルを作成してプログラムを書いていきます。
下記のコマンドを実行して「factory_data.py」ファイルを作成します。
type nul > factory_data.py
 新規ファイルの作成
新規ファイルの作成
ファイルを作成したら、好きなテキストエディタを開いて下記のコードを書いてください。
import numpy as np
from sklearn import svm
from sklearn.metrics import confusion_matrix
data = np.loadtxt('data.csv', delimiter=',')
y = data[:,0].astype(int)
x = data[:,1:3]
clf = svm.SVC(gamma="scale")
# 学習させる
clf.fit(x, y)
data_test = np.loadtxt('data_test.csv', delimiter=',')
test_y = data_test[:,0].astype(int)
test_x = data_test[:,1:3]
print('正解',test_y)
# 学習したデータと比較して推測する
print('推測した結果',clf.predict(test_x))
print('推測した結果の正解率',clf.score(test_x, test_y))
プログラムが書けたら、下記のコマンドでプログラムを実行します。
python factory_data.py
 プログラムを動かす
プログラムを動かす
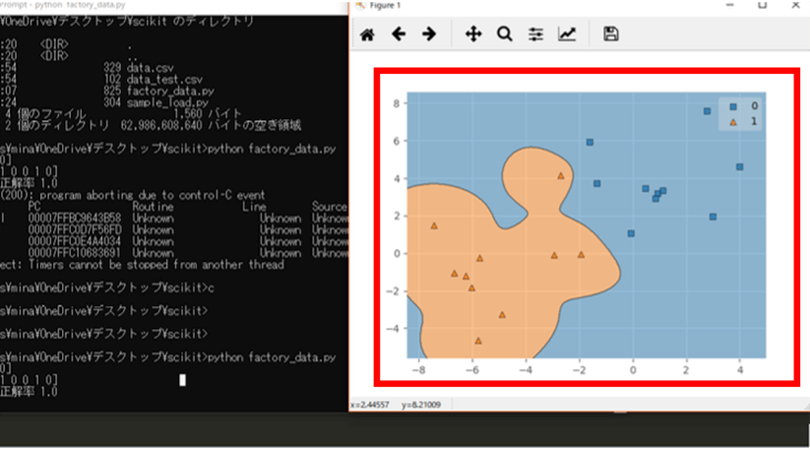
実行結果は下図になりました。
「正解」と表示されている部分が今回推測してほしい結果で、
「推測した結果」の部分がデータから推測した結果、
「推測した結果の正解率」は「正解」と「推測した結果」との正解率を表しています。
下図の通り完全に正解の結果と推測した結果が同じなため、正解率は「1.0」=100%となりました。
 推測した結果
推測した結果
上記で結果が推測できましたが、さらにデータを見やすくするために「データの可視化」を行います。
具体的にはグラフを表示して「良品と不良品」の間に境界線を引いてわかりやすくしたいため、「mlxtend」というライブラリーを使います。
Anacondaの場合は「conda」コマンドを使ってライブラリーのインストールや管理などを行いますが、「mlxtend」もcondaでインストールを行います。
インストールをするためには下記のコマンドを入力して実行します。
conda install -c conda-forge mlxtend
 condaでのインストール
condaでのインストール
mlxtendのインストールに伴い、「factory_data.py」ファイルの中身を下記のコードに変更します。
import numpy as np
import matplotlib.pyplot as pyplot
from sklearn import svm
from sklearn.metrics import confusion_matrix
from mlxtend.plotting import plot_decision_regions
data = np.loadtxt('data.csv', delimiter=',')
y = data[:,0].astype(int)
x = data[:,1:3]
clf = svm.SVC(kernel='linear')
# 学習させる
clf.fit(x, y)
data_test = np.loadtxt('data_test.csv', delimiter=',')
test_y = data_test[:,0].astype(int)
test_x = data_test[:,1:3]
print('正解',test_y)
# 学習したデータと比較して推測する
print('予測した結果',clf.predict(test_x))
print('予測した結果の正解率',clf.score(test_x, test_y))
pyplot.style.use('ggplot')
x_bind = np.vstack((test_x,x))
y_bind = np.hstack((test_y,y))
plot_decision_regions(x_bind, y_bind, clf=clf, res=0.02)
pyplot.show()
主に追記した部分は最後の部分ですが、mlxtendをインストールしたことにより「plot_decision_regions」の部分にデータとターゲットと学習させた分類器を指定するとグラフが描画されます。
実際にプログラムを動かして動作を確認してみます。
下記のコマンドを実行してプログラムを動かしてください。
python factory_data.py
 プログラムを動かす
プログラムを動かす
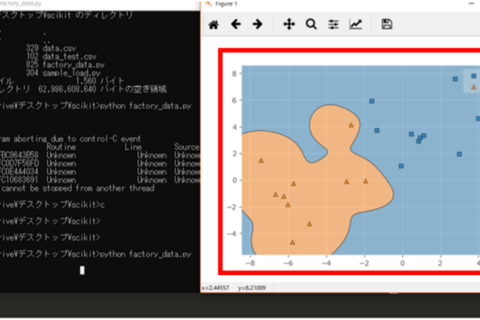
グラフが生成されて、「四角形」と「三角形」の部分に境界線が描画されました。print文で結果が表示されるよりグラフを使用して可視化するとよりわかりやすく分類できていることが確認できました。
 直線で境界線に引かれてグラフが表示される
直線で境界線に引かれてグラフが表示される
今回は、わかりやすいように直線で区別できるように線が引かれていますが、単純に分類という設定だけをしてグラフを表示してみると先ほどと表示が変わります。
「factory_data.py」の
clf = svm.SVC(kernel='linear')
の部分を
clf = svm.SVC(gamma="auto")
と書き換えて再度実行すると、先ほどまで直線で引かれていた境界線が、非線形で引かれて分類されました。
直線で境界線が引かれていた時よりも実際のデータに近い分類になっている印象ですが、実際に線形よりも非線形の方が、自由な境界線を引けるので、精度は高くなります。
 非線形により境界線が細かくなり精度が上がる
非線形により境界線が細かくなり精度が上がる
scikit-learnでSVMは簡単に実装できる
今回はscikit-learnでSVMを用いた機械学習を行ってみましたが、ここまでご説明したように以前はハードルの高かった機械学習を比較的簡単に行うことができます。
scikit-learnには他にも多くのアルゴリズムが実装されており、どのような時にどのアルゴリズムを用いると良いか、選択の助けになる「アルゴリズム・チートシート」と呼ばれるものも用意されています。
“Choosing the right estimator”.2017-2019.scikit-learn developers.
https://scikit-learn.org/stable/tutorial/machine_learning_map/
他のアルゴリズムによる機械学習についても、別の機会にご紹介したいと思います。

石郷祐介
大学卒業後、公設研究機関勤務を経て、「情報科学芸術大学院大学[IAMAS]」に入学。
専門学校講師を経て、企業の研究開発をコンセプトから開発まで支援する「合同会社4D Pocket」代表、エンジニアを養成するフリースクール「一般社団法人HOPTER TECH SCHOOL」代表理事、「名古屋文理大学」及び「名古屋造形大学」非常勤講師。